Layer-wise Vision Injection with Disentangled Attention for Efficient LVLMs
{kind=link}
Abstract
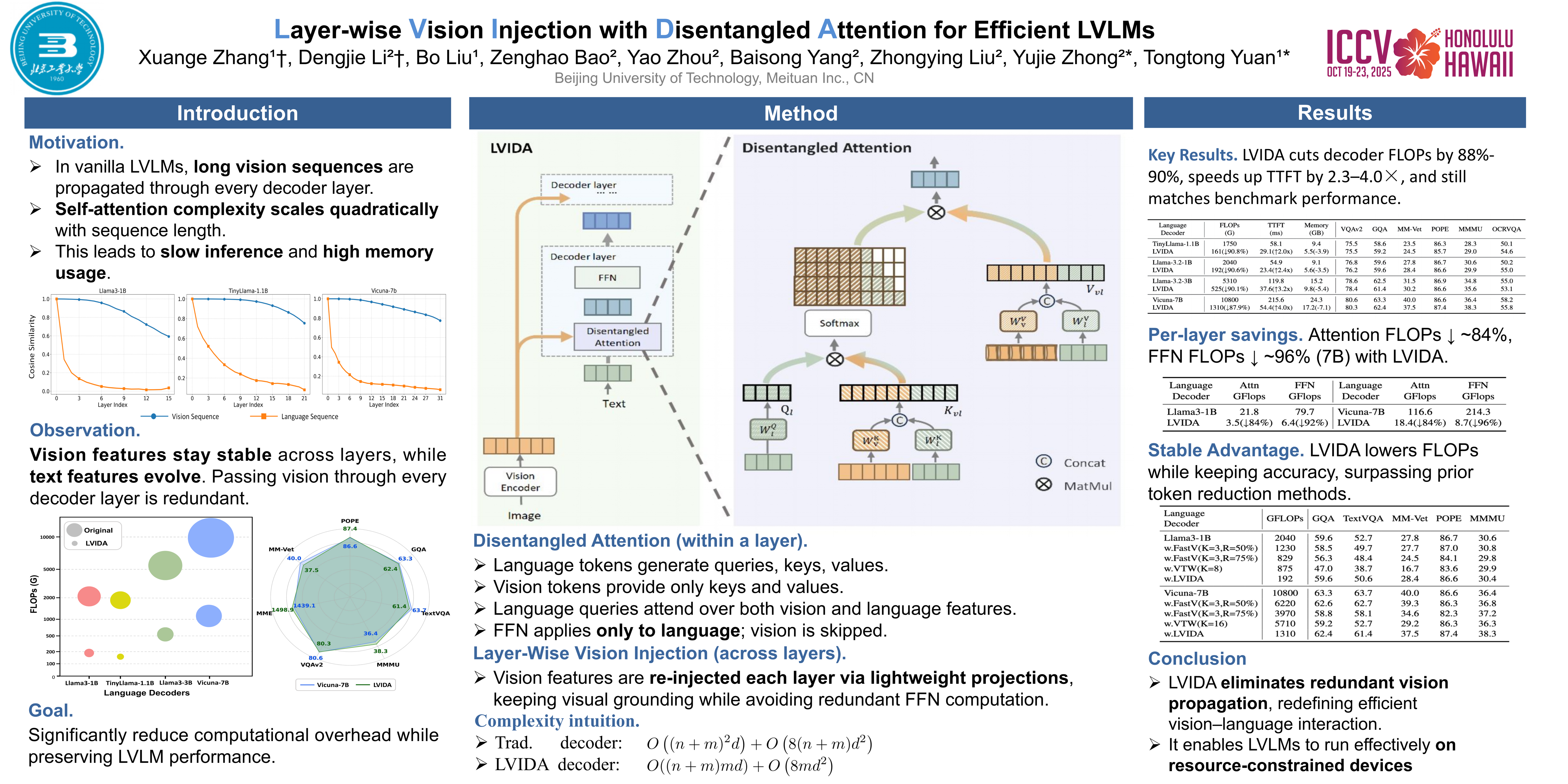
Benefiting from recent advancements in large language models and modality alignment techniques, existing Large Vision-Language Models~(LVLMs) have achieved prominent performance across a wide range of scenarios. However, the excessive computational complexity limits the widespread use of these models in practical applications. We argue that one main bottleneck in computational complexity is caused by the involvement of redundant vision sequences in model computation. This is inspired by a reassessment of the efficiency of vision and language information transmission in the language decoder of LVLMs. Then, we propose a novel vision-language interaction mechanism called Layer-wise Vision Injection with Disentangled Attention (LVIDA). In LVIDA, only the language sequence undergoes full forward propagation, while the vision sequence interacts with the language at specific stages within each language decoder layer. It is striking that our approach significantly reduces computational complexity with minimal performance loss. Specifically, LVIDA achieves approximately a 10× reduction in the computational cost of the language decoder across multiple LVLM models while maintaining comparable performance. Our code will be made publicly available soon.