MaskControl: Spatio-Temporal Control for Masked Motion Synthesis
{kind=link}
Abstract
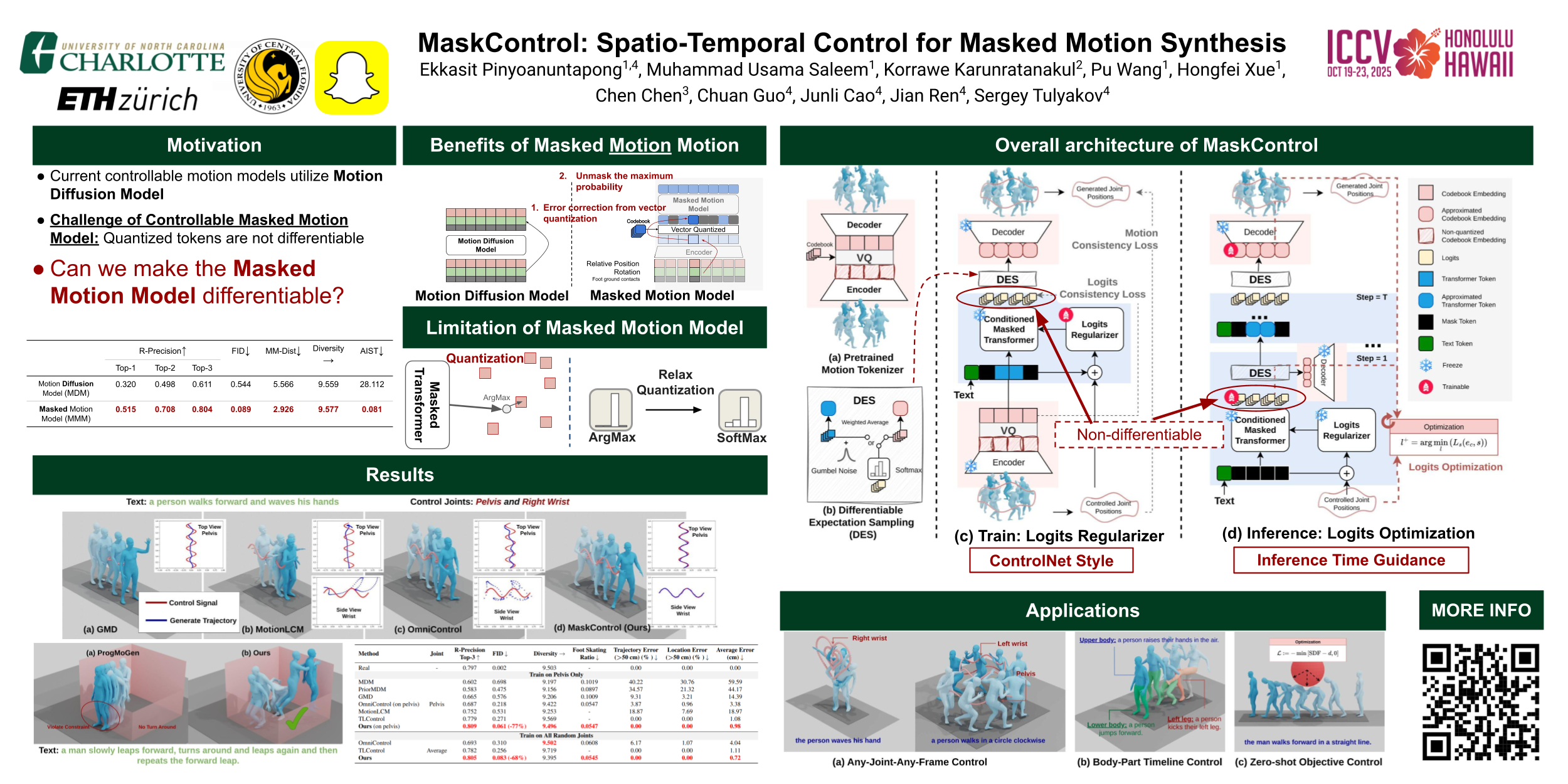
Recent advances in motion diffusion models have enabled spatially controllable text-to-motion generation. However, these models struggle to achieve high-precision control while maintaining high-quality motion generation. To address these challenges, we propose MaskControl, the first approach to introduce controllability to the generative masked motion model. Our approach introduces two key innovations. First, \textit{Logits Regularizer} implicitly perturbs logits at training time to align the distribution of motion tokens with the controlled joint positions, while regularizing the categorical token prediction to ensure high-fidelity generation. Second, \textit{Logit Optimization} explicitly optimizes the predicted logits during inference time, directly reshaping the token distribution that forces the generated motion to accurately align with the controlled joint positions. Moreover, we introduce \textit{Differentiable Expectation Sampling (DES)} to combat the non-differential distribution sampling process encountered by logits regularizer and optimization. Extensive experiments demonstrate that MaskControl outperforms state-of-the-art methods, achieving superior motion quality (FID decreases by ~77\%) and higher control precision (average error 0.91 vs. 1.08). Additionally, MaskControl enables diverse applications, including any-joint-any-frame control, body-part timeline control, and zero-shot objective control. Video visualization can be found at \url{https://anonymous-ai-agent.github.io/CAM}