End-to-End Entity-Predicate Association Reasoning for Dynamic Scene Graph Generation
LiWei Wang ⋅ YanDuo Zhang ⋅ Tao Lu ⋅ Fang Liu ⋅ Huiqin Zhang ⋅ Jiayi Ma ⋅ Huabing Zhou
2025 Poster
{kind=link}
Abstract
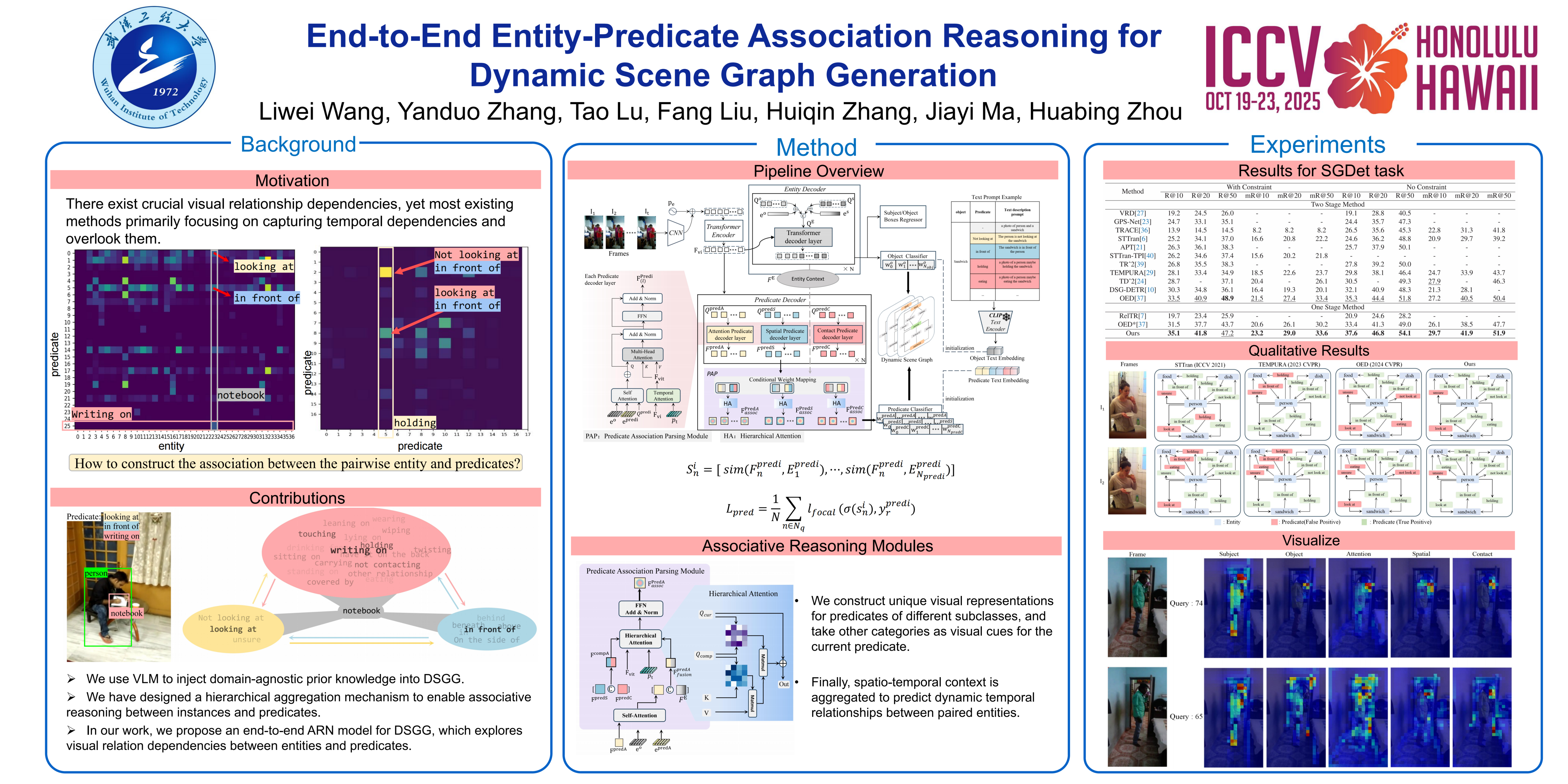
Dynamic Scene Graph Generation (DSGG) aims to comprehensively understand videos by abstracting them into visual triplets $<$\textit{subject}, \textit{predicate}, \textit{object}$>$. Most existing methods focus on capturing temporal dependencies, but overlook crucial visual relationship dependencies between entities and predicates, as well as among predicate subclasses. These dependencies are essential for a deeper contextual understanding of scenarios. Additionally, current approaches do not support end-to-end training and instead rely on a two-stage pipeline, which incurs higher computational costs. To address these issues, we propose an end-to-end \textbf{A}ssociation \textbf{R}easoning \textbf{N}etwork (ARN) for DSGG. ARN leverages CLIP’s semantic priors to model fine-grained triplet cues to generate scene graph. In addition, we design a Predicate Association Parsing (PAP) module that employs a conditional weight mapping mechanism to structure entity and predicate representations. We further introduce a Hierarchical Attention (HA) mechanism to integrate spatio-temporal context with entity and predicate representations, enabling effective associative reasoning. Extensive experiments on the Action Genome dataset demonstrate significant performance improvements over existing methods.
Chat is not available.
Successful Page Load