Trust but Verify: Programmatic VLM Evaluation in the Wild
{kind=link}
Abstract
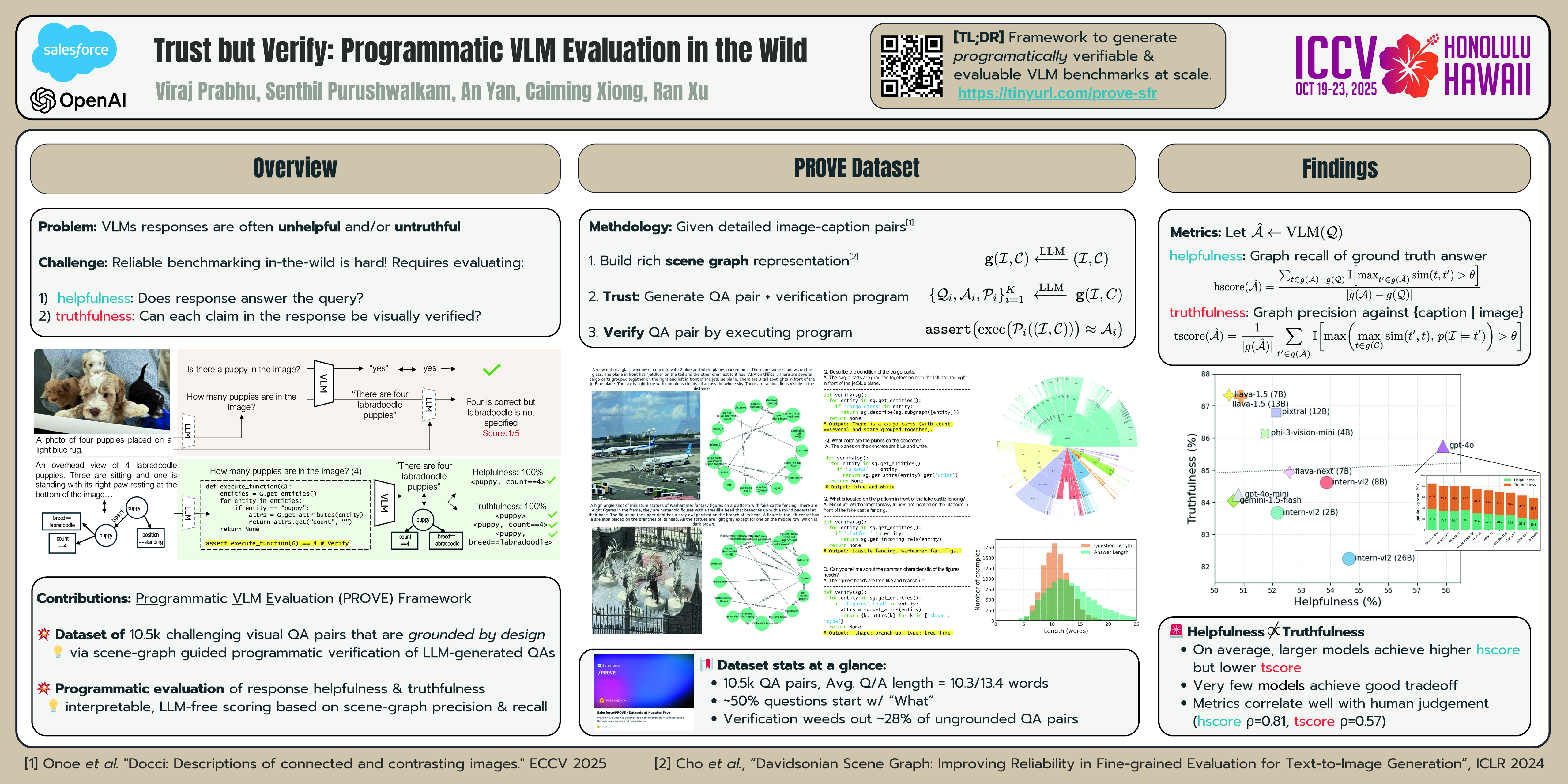
Vision-Language Models (VLMs) frequently hallucinate responses to visual queries, undermining their reliability for critical applications. However, quantifying the effect of such hallucinations in free-form responses to open-ended queries requires visually verifying each claim within the response, which is highly challenging. We propose Programmatic VLM Evaluation (PROVE), a new benchmarking paradigm for evaluating VLM responses to open-ended queries. To construct PROVE, we provide a large language model with a high-fidelity scene-graph representation constructed from a detailed image caption, and prompt it to generate i) diverse and challenging question-answer (QA) pairs that test a range of image understanding capabilities, and ii) programs that can be executed over the scene graph object to verify each QA pair. We thus construct a benchmark of 10.6k challenging but grounded visual QA pairs. Next, we propose a scene graph-based evaluation framework to programmatically measure both the helpfulness and truthfulness of a free-form model response without relying on subjective LLM judgments. We extensively benchmark a range of VLMs on PROVE, and uncover a concerning tradeoff where models that provide more helpful responses often hallucinate more, whereas truthful models tend to be less informative. PROVE serves as a foundation for developing next-generation VLMs that balance helpfulness with truthfulness. A snapshot of our dataset is available at \url{https://prove-explorer-anon.netlify.app/}.