Mobile Video Diffusion
{kind=link}
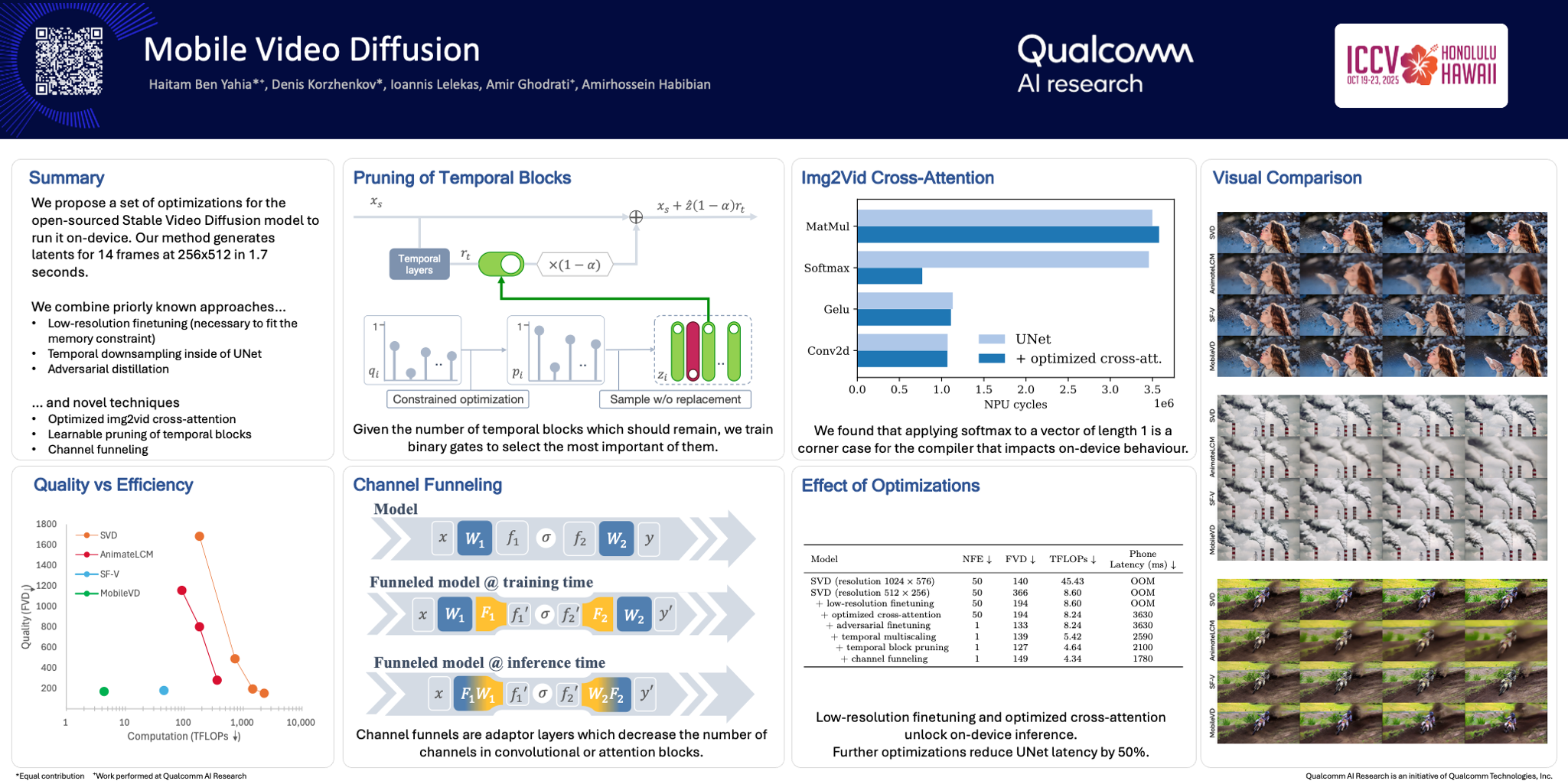
Abstract
Video diffusion models have achieved impressive realism and controllability but are limited by high computational demands, restricting their use on mobile devices. This paper introduces the first mobile-optimized image-to-video diffusion model. Starting from a spatio-temporal UNet from Stable Video Diffusion (SVD), we reduce the computational cost by reducing the frame resolution, incorporating multi-scale temporal representations, and introducing two novel pruning schemas to reduce the number of channels and temporal blocks. Furthermore, we employ adversarial finetuning to reduce the denoising to a single step. Our model, coined as MobileVD, can generate latents for a 14 x 512 x 256 px clip in 1.7 seconds on a Xiaomi-14 Pro, with negligible quality loss.