MaskSAM: Auto-prompt SAM with Mask Classification for Volumetric Medical Image Segmentation
{kind=link}
Abstract
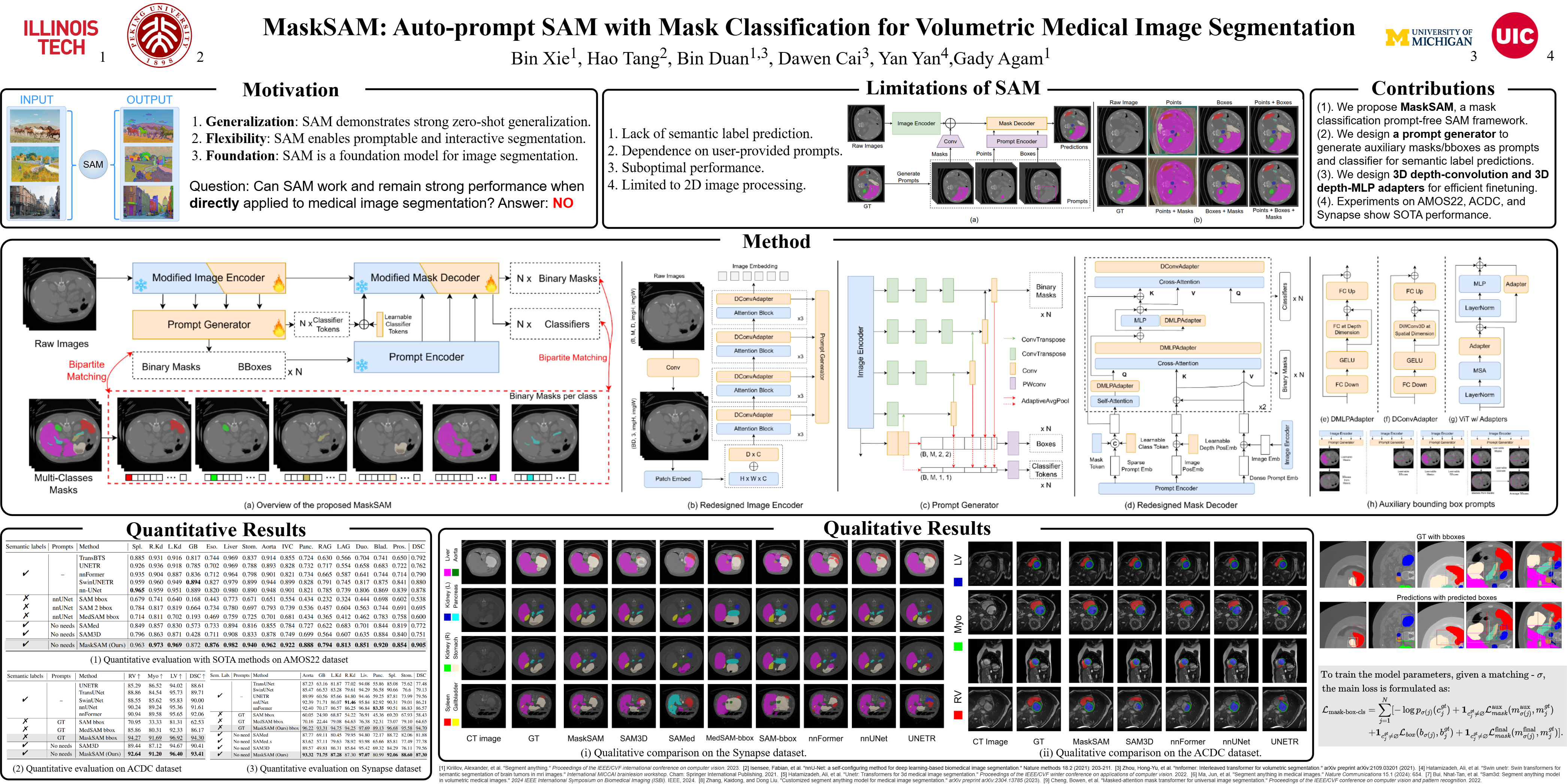
The Segment Anything Model (SAM), a prompt-driven foundation model for natural image segmentation, has demonstrated impressive zero-shot performance. However, SAM is not directly applicable to medical image segmentation due to its inability to predict semantic labels, reliance on additional prompts, and suboptimal performance in this domain. To address these limitations, we propose MaskSAM, a novel prompt-free SAM adaptation framework for medical image segmentation based on mask classification. MaskSAM introduces a prompt generator integrated with SAM’s image encoder to produce auxiliary classifier tokens, binary masks, and bounding boxes. Each pair of auxiliary mask and box prompts eliminates the need for user-provided prompts. Semantic label prediction is enabled by summing the auxiliary classifier tokens with learnable global classifier tokens in SAM’s mask decoder. Additionally, we design a 3D depth-convolution adapter for image embeddings and a 3D depth-MLP adapter for prompt embeddings, which are injected into each transformer block in the image encoder and mask decoder to efficiently fine-tune SAM for volumetric medical imaging.Our method achieves state-of-the-art performance, with a Dice score of 90.52% on AMOS2022, outperforming nnUNet by 2.7%. MaskSAM also surpasses nnUNet by 1.7% on ACDC and 1.0% on the Synapse dataset, demonstrating its effectiveness in medical image segmentation.