SEREP: Semantic Facial Expression Representation for Robust In-the-Wild Capture and Retargeting
{kind=link}
Abstract
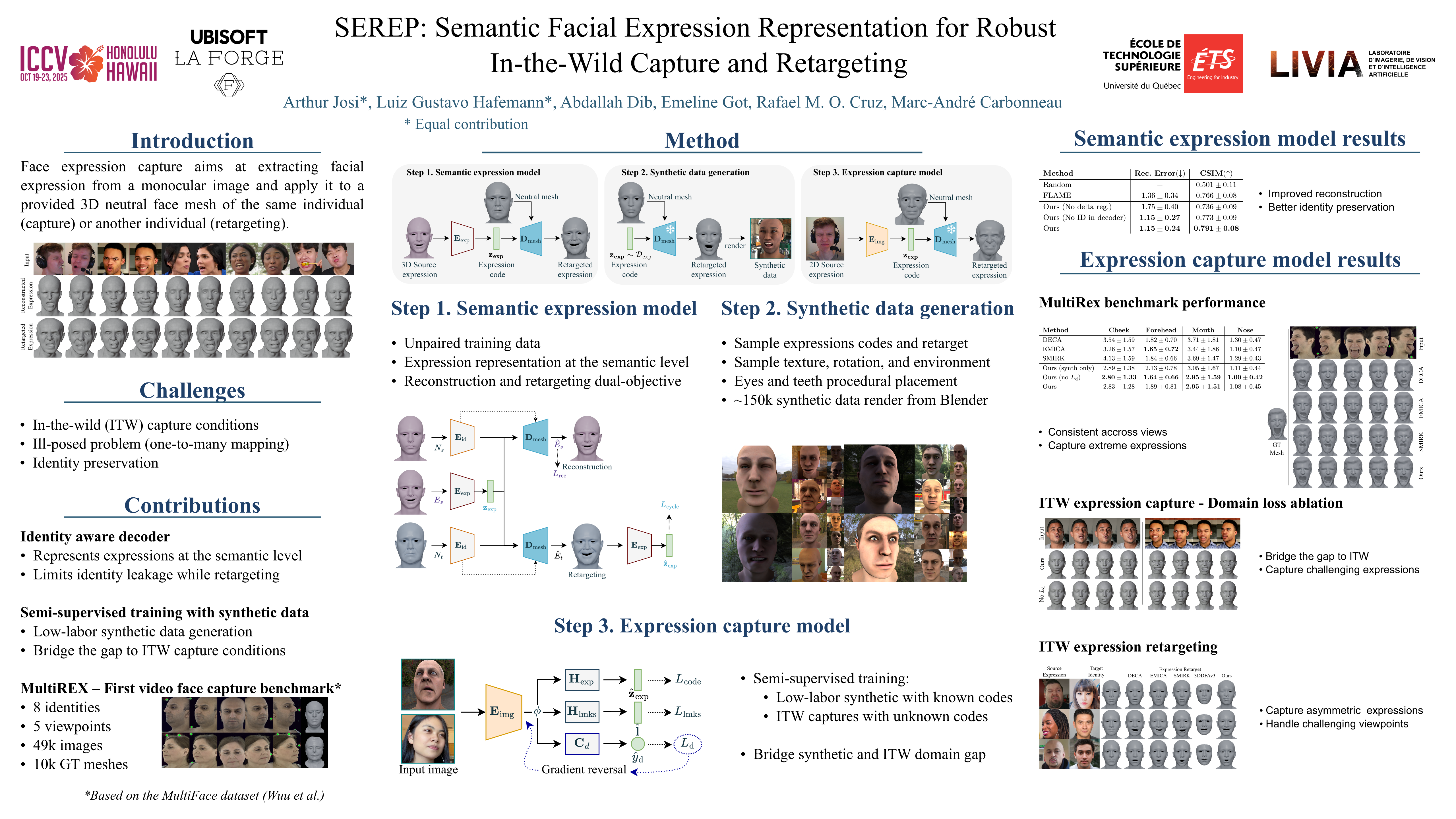
Monocular facial performance capture in-the-wild is challenging due to varied capture conditions, face shapes, and expressions. Most current methods rely on linear 3D Morphable Models, which represent facial expressions independently of identity at the vertex displacement level. We propose SEREP (Semantic Expression Representation), a model that disentangles expression from identity at the semantic level. We start by learning an expression representation from high quality 3D data of unpaired facial expressions. Then, we train a model to predict expression from monocular images relying on a novel semi-supervised scheme using low quality synthetic data. In addition, we introduce MultiREX, a benchmark addressing the lack of evaluation resources for the expression capture task. Our experiments show that SEREP outperforms state-of-the-art methods, capturing challenging expressions and transferring them to new identities.