A Framework for Double-Blind Federated Adaptation of Foundation Models
{kind=link}
Abstract
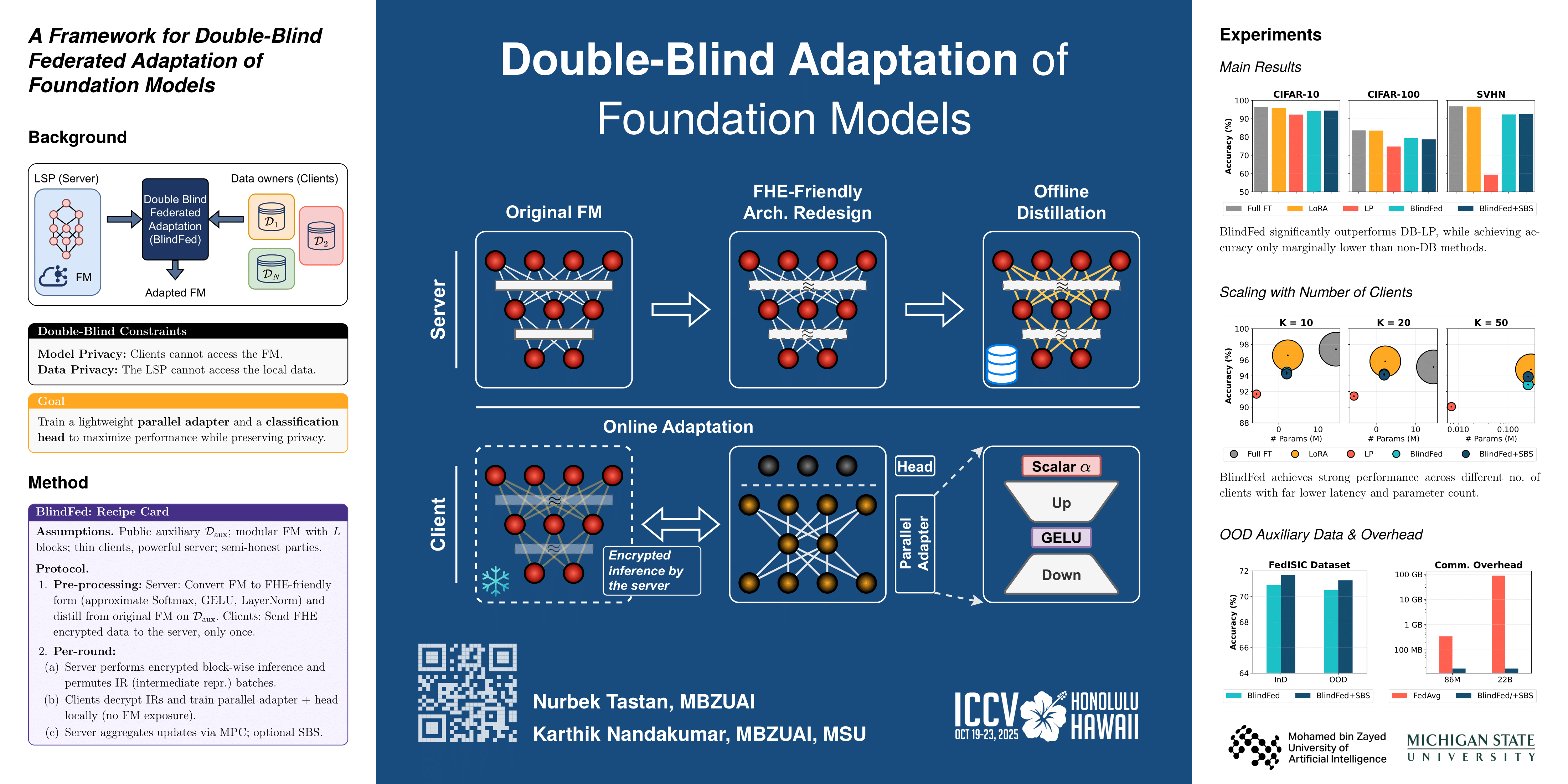
While foundation models (FMs) pre-trained on large-scale data exhibit good zero-shot performance in many downstream tasks, there is often scope for performance improvement via task-specific adaptation of the FM. However, the data required for this adaptation is typically spread across multiple entities (data owners) and cannot be collated at a central location due to privacy concerns. At the same time, a learning service provider (LSP) who owns the FM cannot share the model with data owners due to proprietary reasons. In this work, we propose the BlindFed framework, which enables multiple data owners to collaboratively adapt an FM (owned by an LSP) for a specific downstream task while preserving the interests of both the data owners and the LSP. Specifically, data owners do not see the FM as well as each other's data, and the LSP does not see sensitive task-specific data. The BlindFed framework relies on fully homomorphic encryption (FHE) and consists of three key innovations: (i) We introduce FHE-friendly architectural modifications of the given FM, leveraging existing tools such as polynomial approximations and low-rank parallel adapters. (ii) We propose a two-stage split learning process, where FHE-friendly FM blocks are learned through offline knowledge distillation and task-specific local parallel adapters are learned via online encrypted inference without backpropagation through the FM. (iii) Since local adapter learning requires the LSP to share intermediate representations with the data owners, we propose a privacy-boosting scheme based on sample permutations within a batch and stochastic block sampling to prevent data owners from learning the FM through model extraction attacks. Empirical results on four image classification datasets demonstrate the practical feasibility of the BlindFed framework, albeit at a high communication cost and large computational complexity for the LSP.