monoVLN: Bridging the Observation Gap between Monocular and Panoramic Vision and Language Navigation
{kind=link}
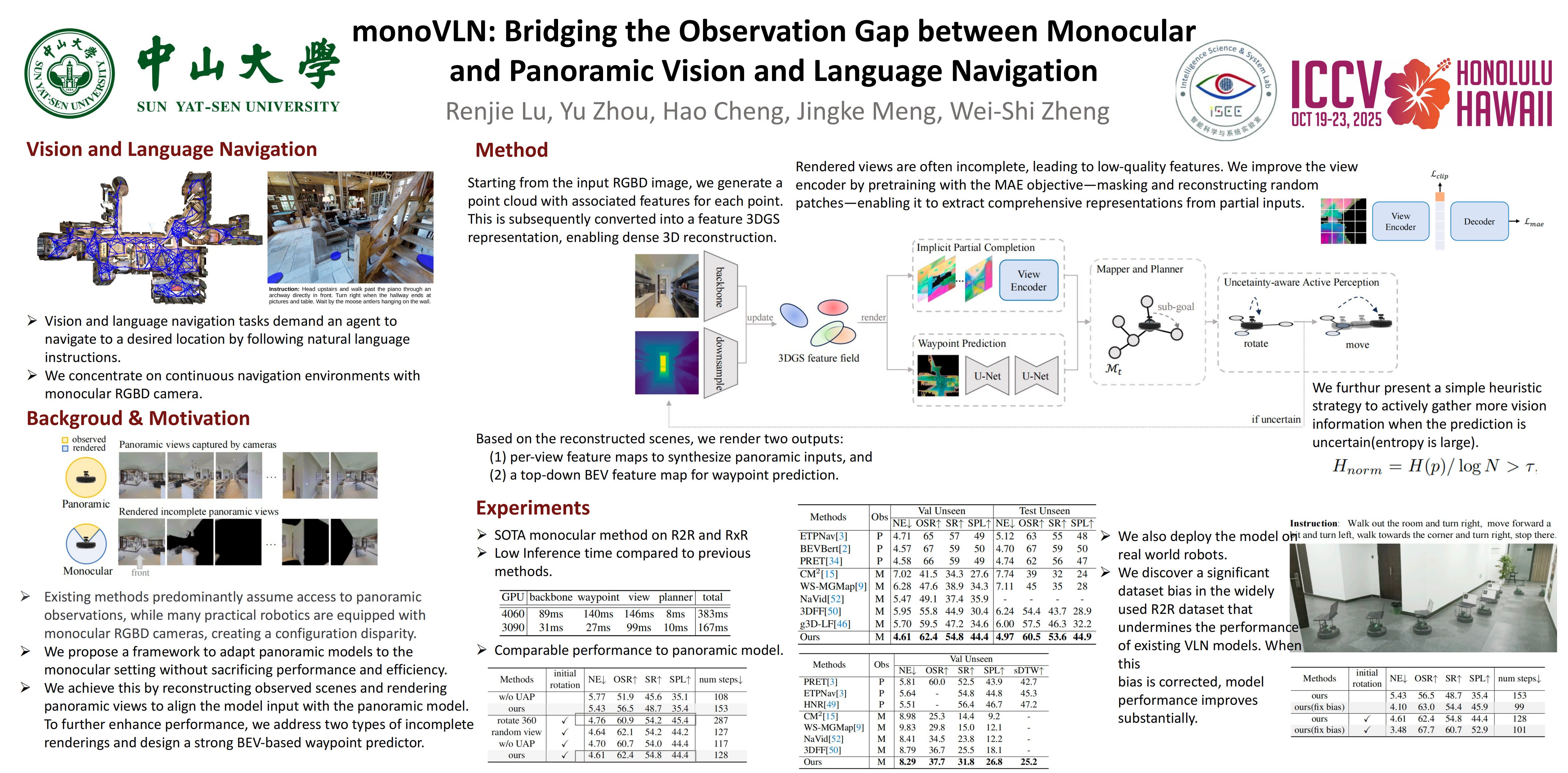
Abstract
Vision and Language Navigation(VLN) requires agents to navigate 3D environments by following natural language instructions. While existing methods predominantly assume access to panoramic observations, many practical robotics are equipped with monocular RGBD cameras, creating a significant configuration disparity. In this work, we address this critical gap by developing a novel 3DGS-based framework for monocular VLN agents, focusing on the intrinsic information incompleteness challenge. Our approach incorporates two key innovations: (1) implicit partial completion module for inferring representations of missing regions in incompletely rendered panoramic feature maps, and (2) an uncertainty-aware active perception strategy that enables the agent to actively acquire visual observation when uncertain about its decision. Extensive experiments on R2R-CE and RxR-CE datasets demonstrate that our monoVLN outperforms all existing monocular methods, significantly improve 8\% success rate on R2R-CE compared to previous monocular methods. We also validate our monoVLN in real-world environments, providing a practical solution for real-world VLN. Furthermore, our findings challenge the conventional wisdom regarding panoramic observations, suggesting they may not be the optimal configuration and providing insights for future research directions in VLN literature. Code will be released.