COVTrack: Continuous Open-Vocabulary Tracking via Adaptive Multi-Cue Fusion
{kind=link}
Abstract
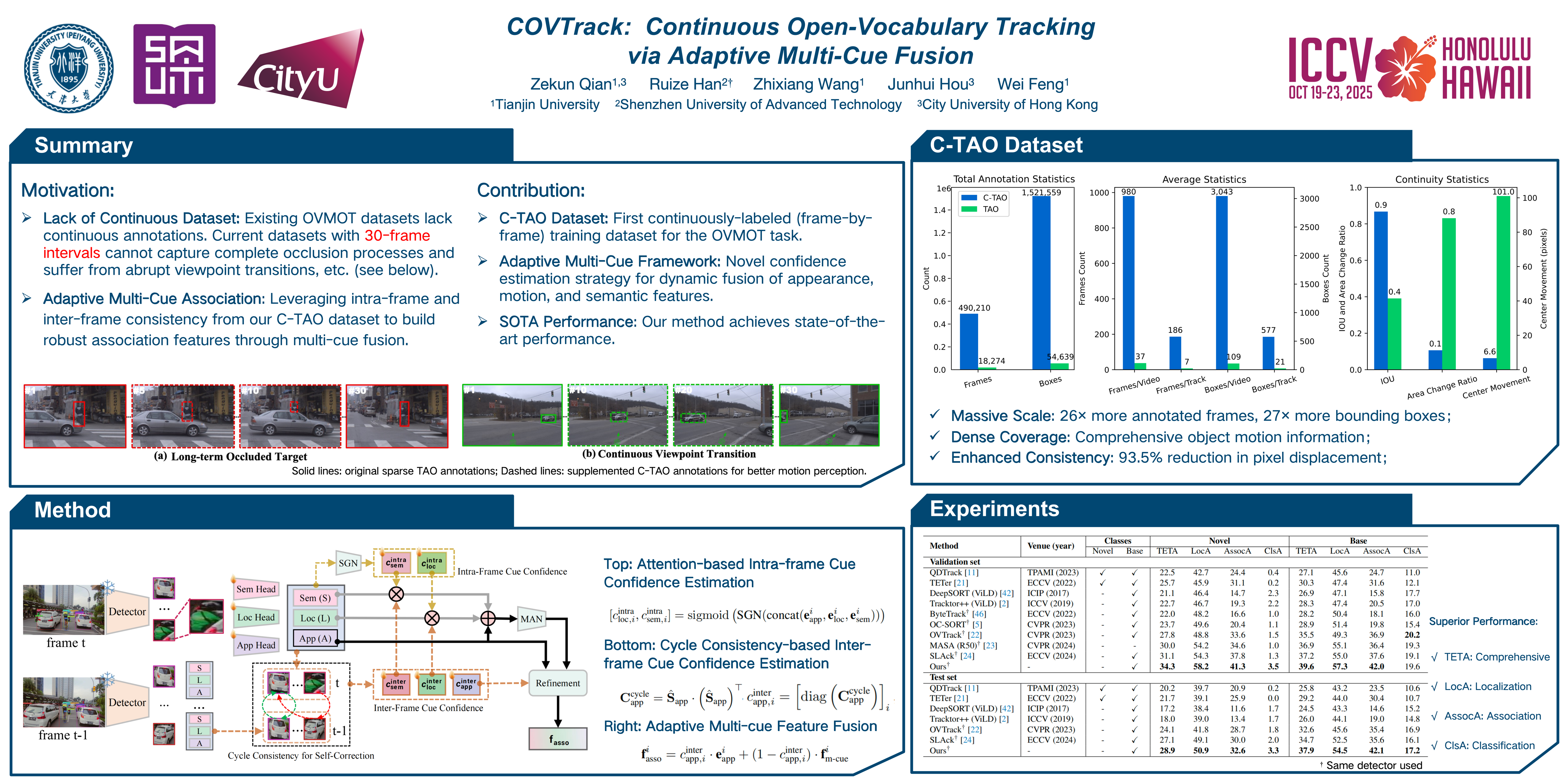
Open-Vocabulary Multi-Object Tracking (OVMOT) aims to detect and track diverse object categories in videos, including both seen (base) and unseen (novel) categories. Current methods rely on appearance features from generated image pairs or utilize the discontinuous annotations of the video dataset (TAO) for training, primarily due to the lack of available continuous annotated video datasets for OVMOT. This limitation affects their effectiveness, since continuous target trajectories are necessary for robust tracker learning.In this work, we propose the C-TAO dataset, which provides a continuous version of TAO, thereby constructing the first continuous annotated training dataset for OVMOT. This addresses the previous limitations in training data availability. Additionally, we introduce COVTrack, a unified framework that effectively integrates motion and semantic features with appearance features, in which the multi-cue feature aggregation strategy dynamically aggregates and balances these features, based on the confidence estimation from both intra-frame and inter-frame contexts.Our proposed framework significantly improves OVMOT performance, establishing COVTrack as a state-of-the-art solution on OVMOT benchmarks.