You Think, You ACT: The New Task of Arbitrary Text to Motion Generation
{kind=link}
Abstract
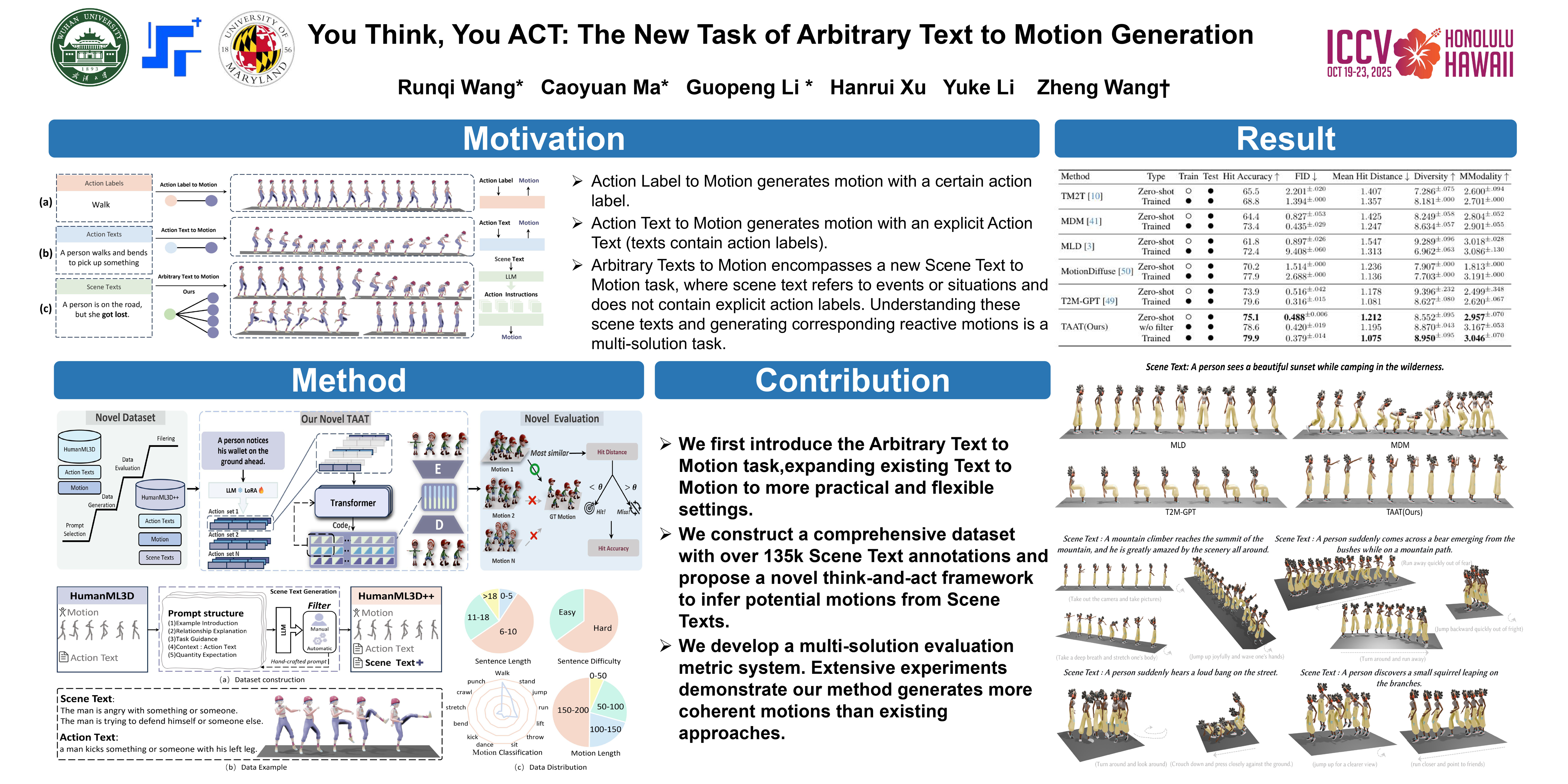
Text to Motion aims to generate human motions from texts. Existing settings rely on limited Action Texts that include action labels (e.g., "walk, bend"), which limits flexibility and practicability in scenarios difficult to describe directly. This paper extends limited Action Texts to arbitrary ones. Scene texts without explicit action labels can enhance the practicality of models in complex and diverse industries such as virtual human interaction, robot behavior generation, and film production, while also supporting the exploration of potential implicit behavior patterns. However, newly introduced Scene Texts may yield multiple reasonable output results, causing significant challenges in existing data, framework, and evaluation.To address this practical issue, we first create a new dataset, HumanML3D++, by extending texts of the largest existing dataset, HumanML3D. Secondly, we propose a simple yet effective framework that extracts action instructions from arbitrary texts and subsequently generates motions. Furthermore, we also benchmark this new setting with multi-solution metrics to address the inadequacies of existing single-solution metrics. Extensive experiments indicate that Text to Motion in this realistic setting is challenging, fostering new research in this practical direction. Our data, model, and code will be released.