Unbiased Region-Language Alignment for Open-Vocabulary Dense Prediction
{kind=link}
Abstract
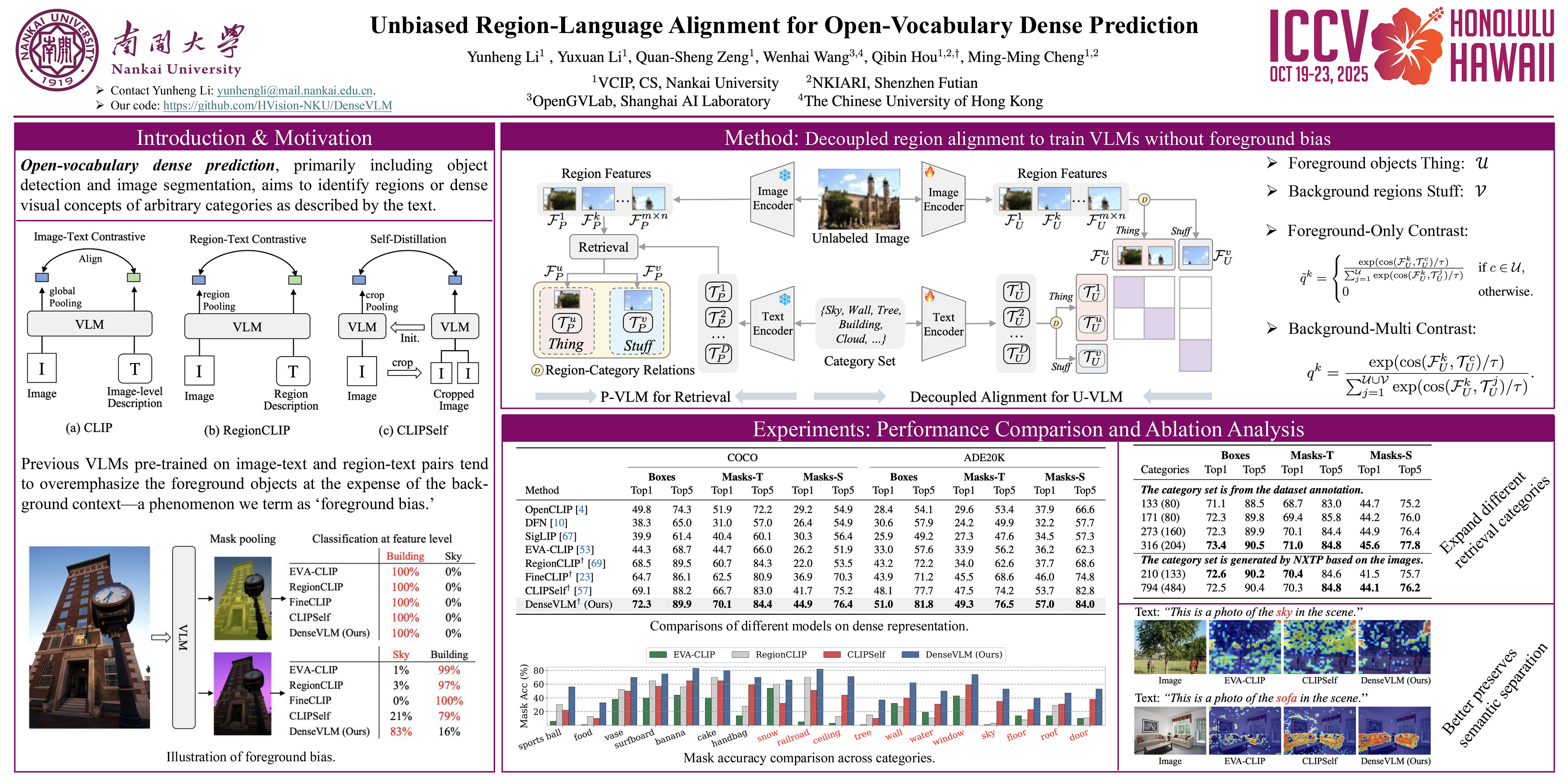
Pre-trained vision-language models (VLMs), such as CLIP, have demonstrated impressive zero-shot recognition capability, but still underperform in dense prediction tasks. Self-distillation recently is emerging as a promising approach for fine-tuning VLMs to better adapt to local regions without requiring extensive annotations. However, previous state-of-the-art approaches often suffer from significant `foreground bias', where models tend to wrongly identify background regions as foreground objects. To alleviate this issue, we propose DenseVLM, a framework designed to learn unbiased region-language alignment from powerful pre-trained VLM representations. To alleviate this issue, we propose DenseVLM, a framework designed to learn unbiased region-language alignment from powerful pre-trained VLM representations. DenseVLM leverages the pre-trained VLM to retrieve categories for unlabeled regions and then decouples the interference between foreground and background features. We show that DenseVLM can directly replace the original VLM in open-vocabulary object detection and image segmentation methods, leading to notable performance improvements. Furthermore, it exhibits promising zero-shot scalability when training on more extensive and diverse datasets. Our code is available in the supplementary materials and will be publicly released.