TriDi: Trilateral Diffusion of 3D Humans, Objects, and Interactions
{kind=link}
Abstract
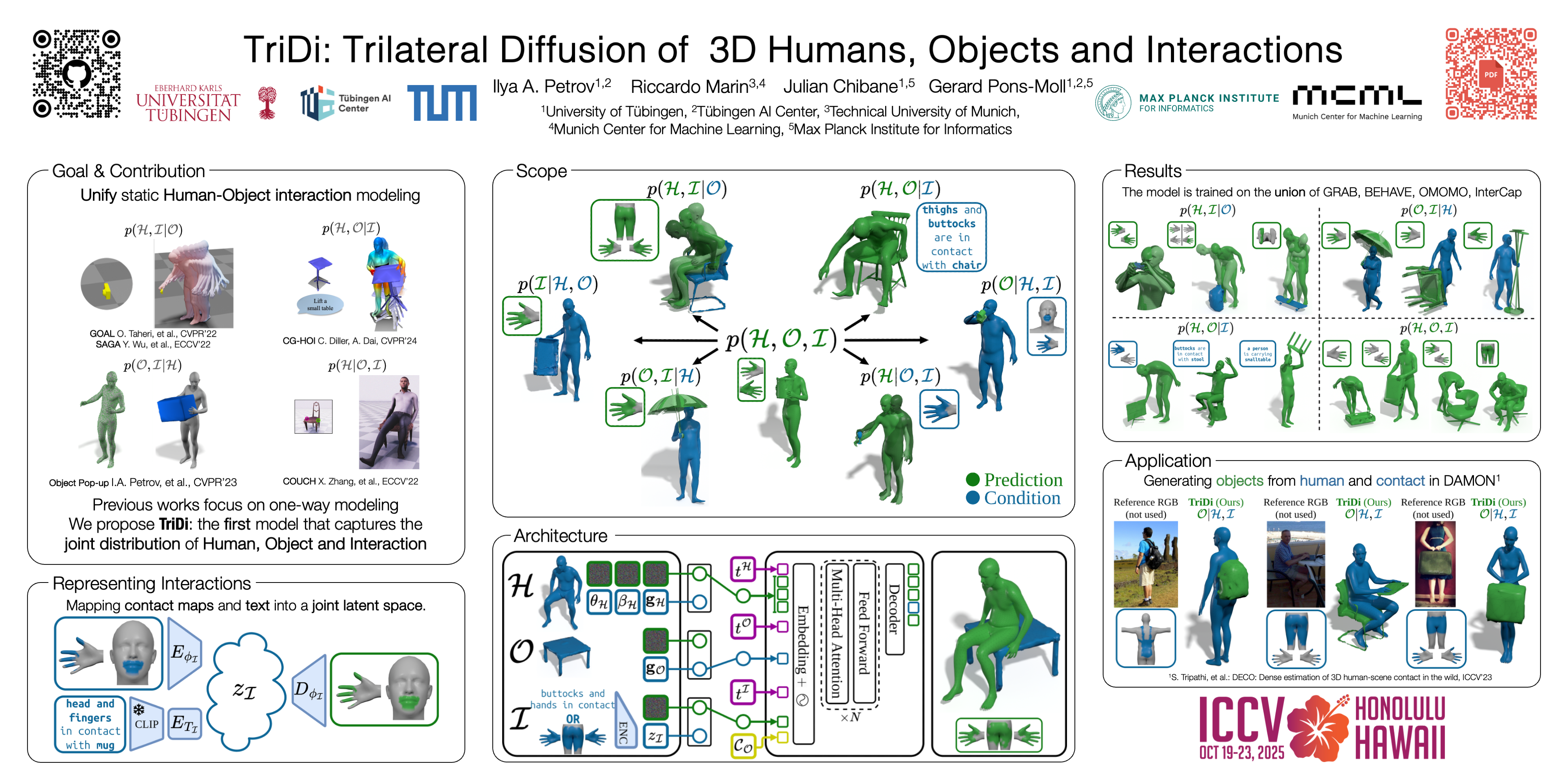
Modeling 3D human-object interaction (HOI) is a problem of great interest for computer vision and a key enabler for virtual and mixed-reality applications. Existing methods work in a one-way direction: some recover plausible human interactions conditioned on a 3D object; others recover the object pose conditioned on a human pose. Instead, we provide the first unified model - TriDi which works in any direction. Concretely, we generate Human, Object, and Interaction modalities simultaneously with a new three-way diffusion process, allowing to model seven distributions with one network. We implement TriDi as a transformer attending to the various modalities' tokens, thereby discovering conditional relations between them. The user can control the interaction either as a text description of HOI or a contact map. We embed these two representations onto a shared latent space, combining the practicality of text descriptions with the expressiveness of contact maps. Using a single network, TriDi unifies all the special cases of prior work and extends to new ones modeling a family of seven distributions. Remarkably, despite using a single model, TriDi generated samples surpass one-way specialized baselines on GRAB and BEHAVE in terms of both qualitative and quantitative metrics, and demonstrating better diversity. We show applicability of TriDi to scene population, generating object for human-contact datasets, and generalization to unseen object geometry.