Dataset Ownership Verification for Pre-trained Masked Models
Yuechen Xie ⋅ Jie Song ⋅ Yicheng Shan ⋅ Xiaoyan Zhang ⋅ Yuanyu Wan ⋅ Shengxuming Zhang ⋅ Jiarui Duan ⋅ Mingli Song
2025 Poster
{kind=link}
Abstract
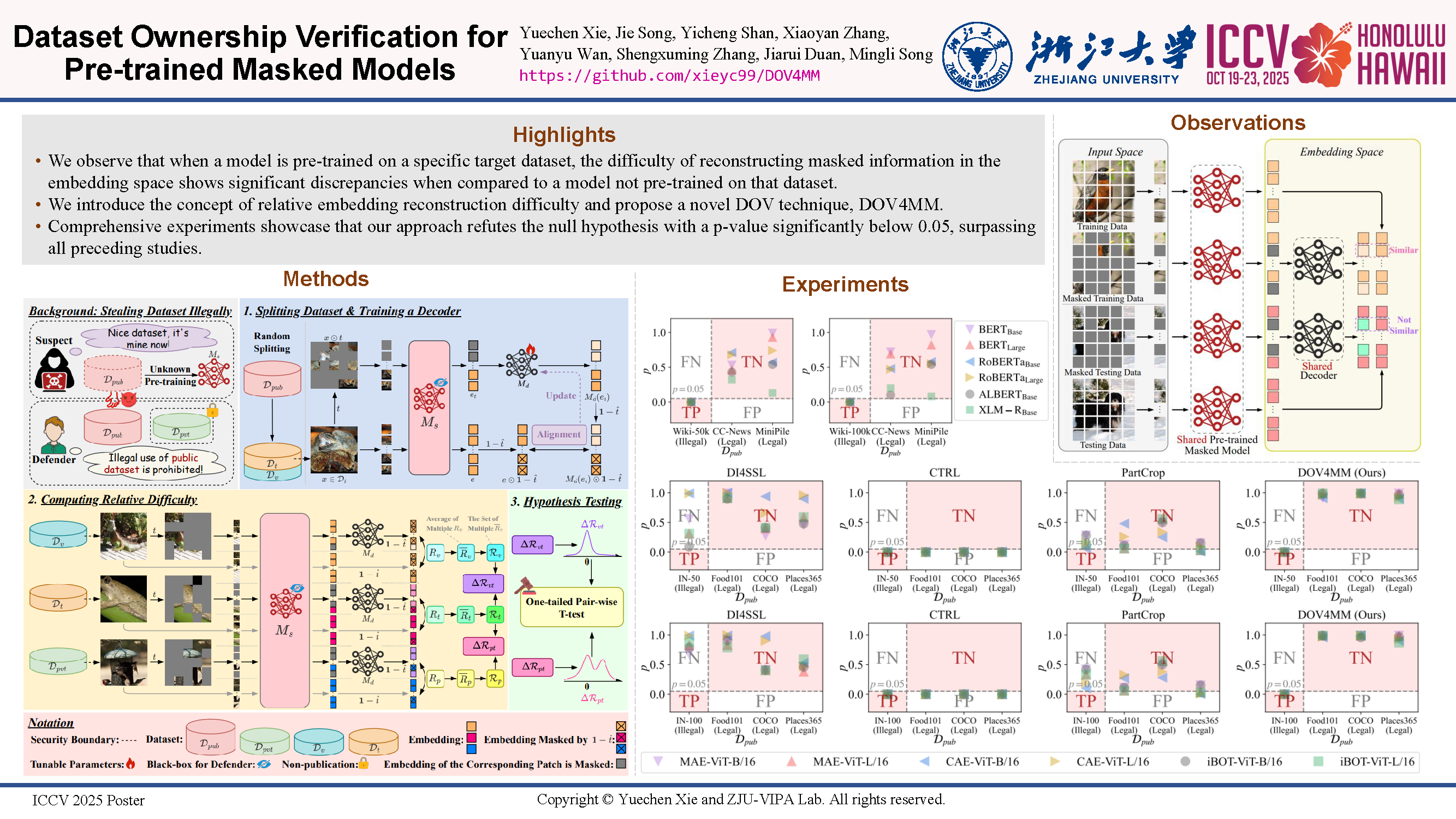
High-quality open-source datasets have emerged as a pivotal catalyst driving the swift advancement of deep learning, while facing the looming threat of potential exploitation. Protecting these datasets is of paramount importance for the interests of their owners. The verification of dataset ownership has evolved into a crucial approach in this domain; however, existing verification techniques are predominantly tailored to supervised models and contrastive pre-trained models, rendering them ill-suited for direct application to the increasingly prevalent masked models. In this work, we introduce the inaugural methodology addressing this critical, yet unresolved challenge, termed Dataset Ownership Verification for Masked Modeling (DOV4MM). The central objective is to ascertain whether a suspicious black-box model has been pre-trained on a particular unlabeled dataset, thereby assisting dataset owners in safeguarding their rights. DOV4MM is grounded in our empirical observation that when a model is pre-trained on the target dataset, the difficulty of reconstructing masked information within the embedding space exhibits a marked contrast to models not pre-trained on that dataset. We validated the efficacy of DOV4MM through ten masked image models on ImageNet-1K and four masked language models on WikiText-103. The results demonstrate that DOV4MM rejects the null hypothesis, with a $p$-value considerably below 0.05, surpassing all prior approaches.
Chat is not available.
Successful Page Load