FreeCus: Free Lunch Subject-driven Customization in Diffusion Transformers
{kind=link}
Abstract
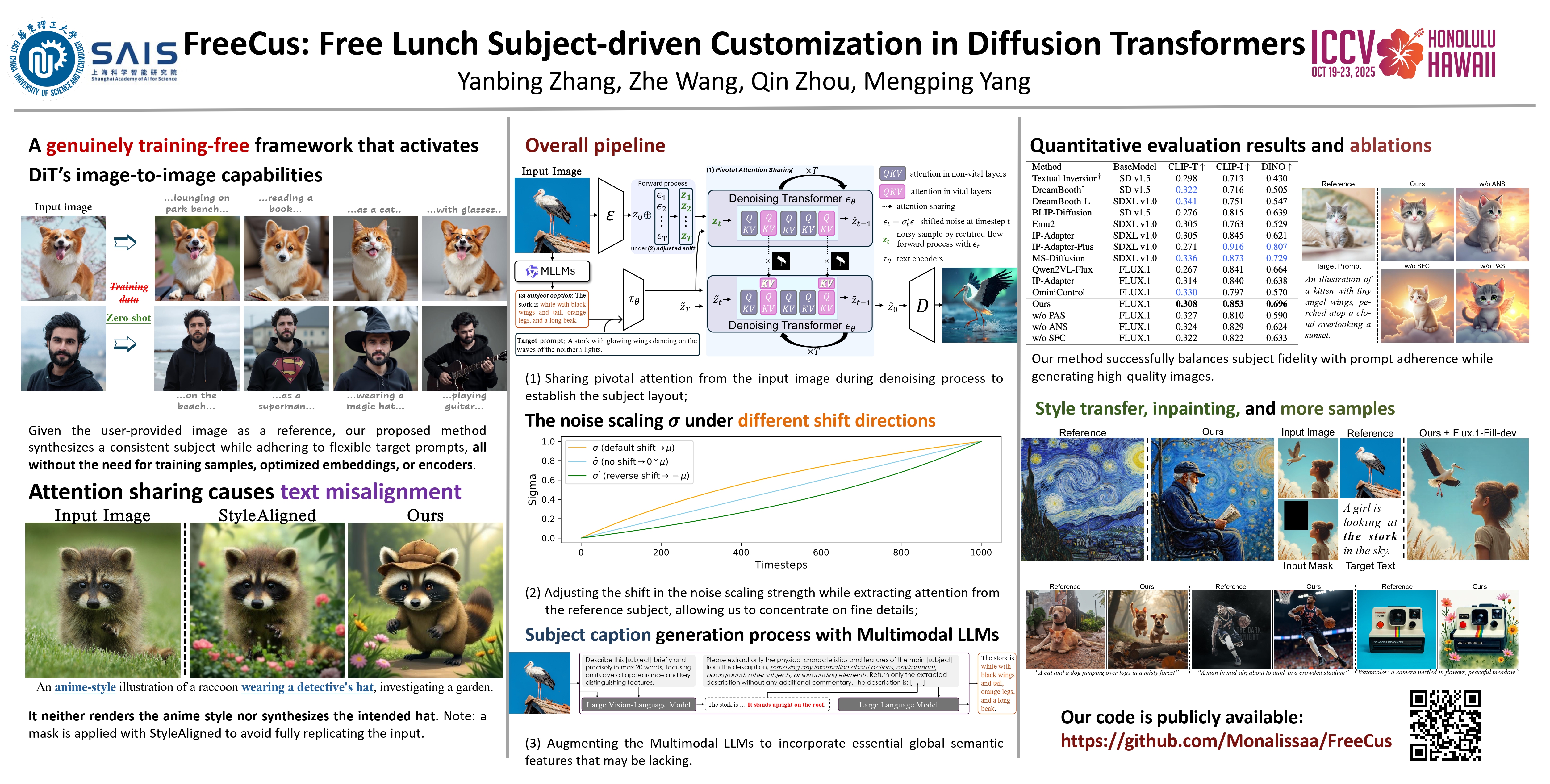
In light of recent breakthroughs in text-to-image (T2I) generation, particularly with diffusion transformers (DiT), subject-driven technologies are increasingly being employed for high-fidelity customized production that preserves subject identity from reference inputs, enabling thrilling design workflows and engaging entertainment. Existing alternatives typically require either per-subject optimization via trainable text embeddings or training specialized encoders for subject feature extraction on large-scale datasets. Such dependencies on training procedures fundamentally constrain their practical applications. More importantly, current methodologies fail to fully leverage the inherent zero-shot potential of modern diffusion transformers (e.g., the Flux series) for authentic subject-driven synthesis. To bridge this gap, we propose FreeCus, a genuinely training-free framework that activates DiT's capabilities through three key innovations: 1) We introduce a pivotal attention sharing mechanism that captures the subject's layout integrity while preserving crucial editing flexibility. 2) Through a straightforward analysis of DiT's dynamic shifting, we propose an upgraded variant that significantly improves fine-grained feature extraction. 3) We further integrate advanced Multimodal Large Language Models (MLLMs) to enrich cross-modal semantic representations. Extensive experiments reflect that our method successfully unlocks DiT's zero-shot ability for consistent subject synthesis across diverse contexts, achieving state-of-the-art or comparable results compared to approaches that require additional training. Notably, our framework demonstrates seamless compatibility with existing inpainting pipelines and control modules, facilitating more compelling experiences.