REDUCIO! Generating 1K Video within 16 Seconds using Extremely Compressed Motion Latents
Rui Tian ⋅ Qi Dai ⋅ Jianmin Bao ⋅ Kai Qiu ⋅ Yifan Yang ⋅ Chong Luo ⋅ Zuxuan Wu ⋅ Yu-Gang Jiang
2025 Poster
{kind=link}
Abstract
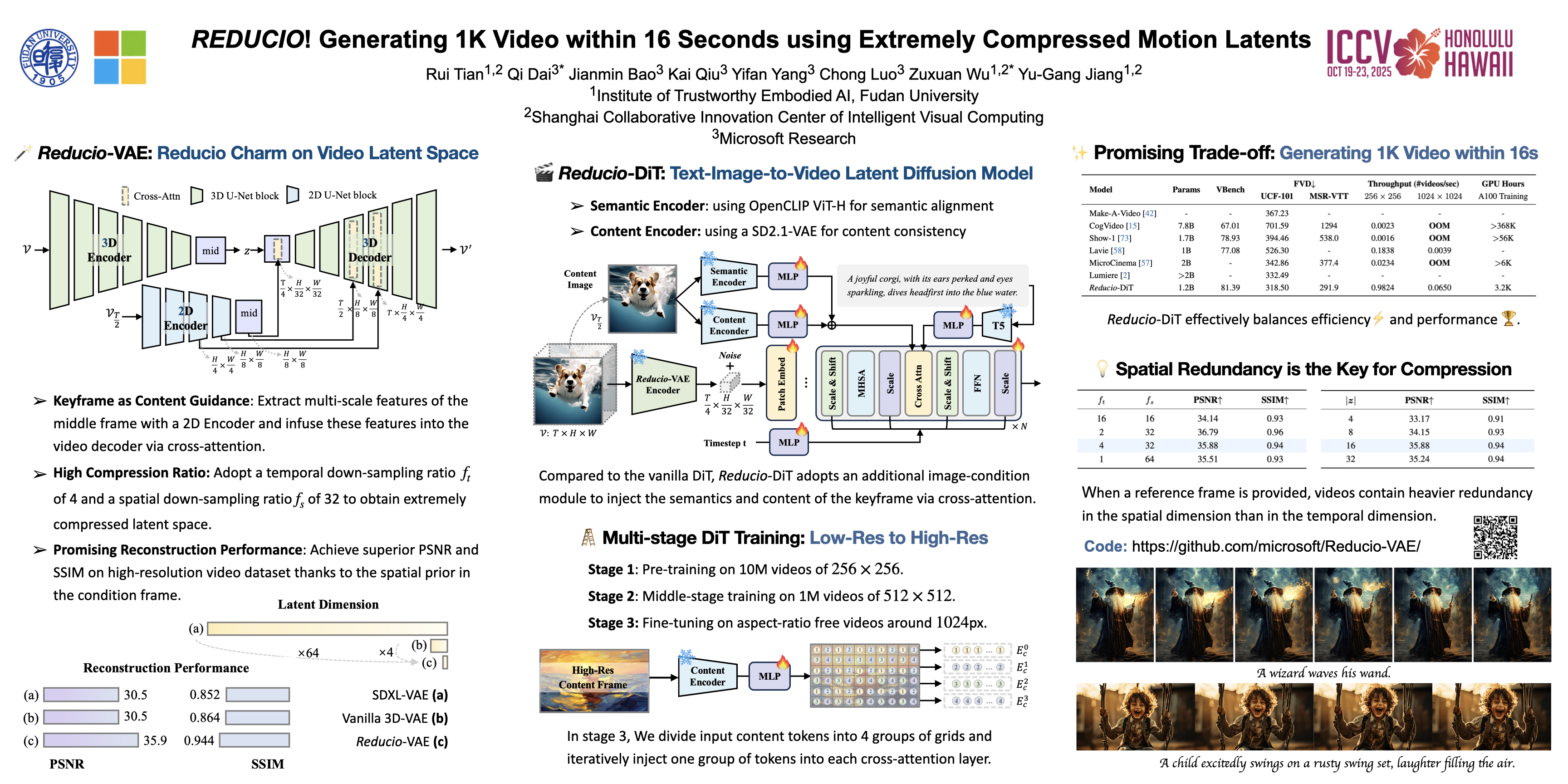
Commercial video generation models have exhibited realistic, high-fidelity results but are still restricted to limited access.One crucial obstacle for large-scale applications is the expensive training and inference cost.In this paper, we argue that videos contain significantly more redundant information than images, allowing them to be encoded with very few motion latents.Towards this goal, we design an image-conditioned VAE that projects videos into extremely compressed latent space and decode them based on content images. This magic Reducio charm enables 64$\times$ reduction of latents compared to a common 2D VAE, without sacrificing the quality.Building upon Reducio-VAE, we can train diffusion models for high-resolution video generation efficiently. Specifically, we adopt a two-stage generation paradigm, first generating a condition image via text-to-image generation, followed by text-image-to-video generation with the proposed Reducio-DiT. Extensive experiments show that our model achieves strong performance in evaluation.More importantly, our method significantly boosts the training and inference efficiency of video LDMs. Reducio-DiT is trained in just 3.2K A100 GPU hours in total and can generate a 16-frame 1024$\times$1024 video clip within 15.5 seconds on a single A100 GPU.
Chat is not available.
Successful Page Load