EVT: Efficient View Transformation for Multi-Modal 3D Object Detection
{kind=link}
Abstract
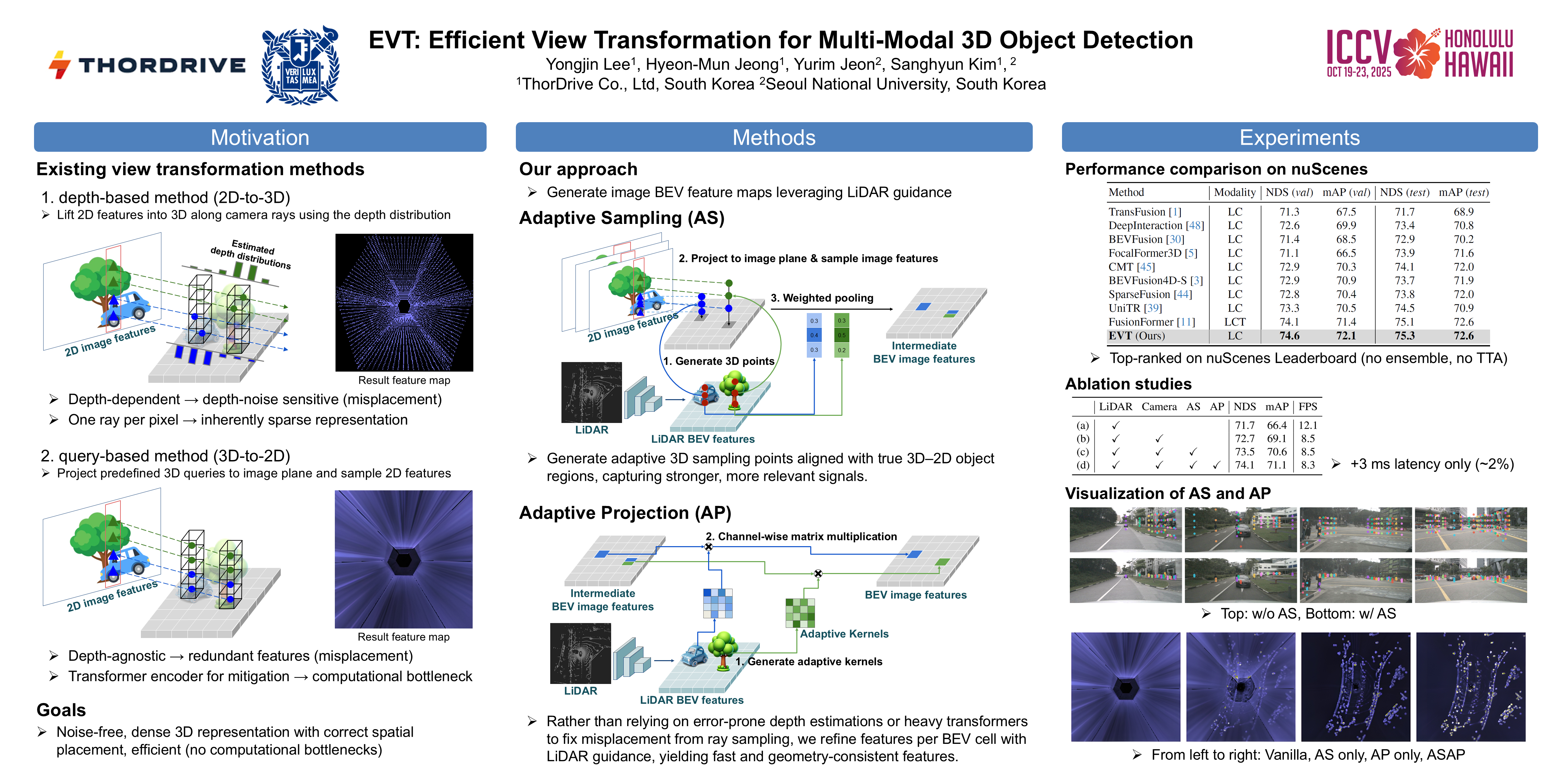
Multi-modal sensor fusion in Bird’s Eye View (BEV) representation has become the leading approach for 3D object detection. However, existing methods often rely on depth estimators or transformer encoders to transform image features into BEV space, which reduces robustness or introduces significant computational overhead. Moreover, the insufficient geometric guidance in view transformation results in ray-directional misalignments, limiting the effectiveness of BEV representations. To address these challenges, we propose Efficient View Transformation (EVT), a novel 3D object detection framework that constructs a well-structured BEV representation, improving both accuracy and efficiency. Our approach focuses on two key aspects. First, Adaptive Sampling and Adaptive Projection (ASAP), which utilizes LiDAR guidance to generate 3D sampling points and adaptive kernels, enables more effective transformation of image features into BEV space and a refined BEV representation. Second, an improved query-based detection framework, incorporating group-wise mixed query selection and geometry-aware cross-attention, effectively captures both the common properties and the geometric structure of objects in the transformer decoder. On the nuScenes test set, EVT achieves state-of-the-art performance of 75.3\% NDS with real-time inference speed.