Free-MoRef: Instantly Multiplexing Context Perception Capabilities of Video-MLLMs within Single Inference
KUO WANG ⋅ Quanlong Zheng ⋅ Junlin Xie ⋅ Yanhao Zhang ⋅ Jinguo Luo ⋅ Haonan Lu ⋅ Liang Lin ⋅ Fan Zhou ⋅ Guanbin Li
2025 Poster
{kind=link}
Abstract
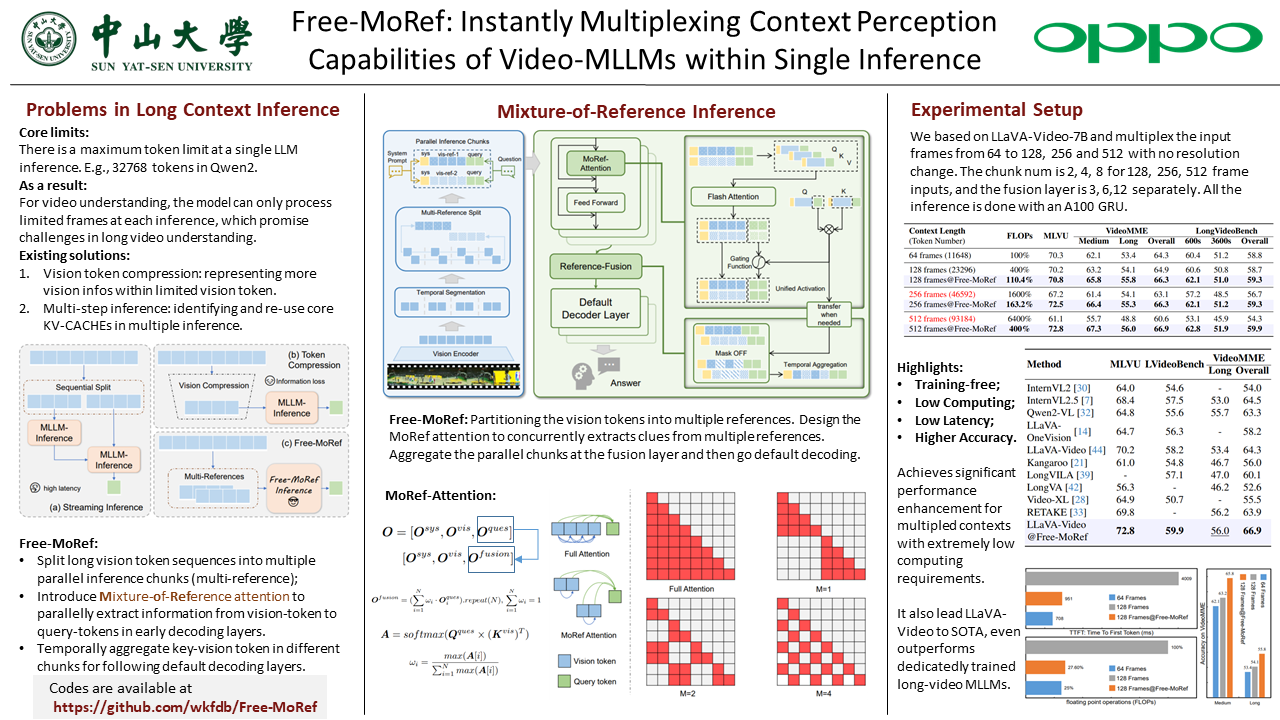
Video Multimodal Large Language Models~(Video-MLLM) have achieved remarkable advancements in video understanding tasks. However, constrained by the context length limitation in the underlying LLMs, existing Video-MLLMs typically exhibit suboptimal performance on long video scenarios. To understand extended input frames, common solutions span token compression and streaming inference techniques, which sacrifice feature granularity or inference efficiency. Differently, to efficiently achieve comprehensive understanding of longer frame inputs, we draw ideas from MoE and propose a training-free approach Free-MoRef, which instantly multiplexes the context perception capabilities of Video-MLLMs within one inference pass. Specifically, Free-MoRef reconstructs the vision tokens into several short sequences as multi-references. Subsequently, we introduce MoRef-attention, which gathers clues from the multi-reference chunks in parallel to summarize unified query activations. After the shadow layers in LLMs, a reference fusion step is derived to compose a final mixed reasoning sequence with key tokens from parallel chunks, which compensates the cross-reference vision interactions that are neglected in MoRef-attention. By splitting and fusing the long vision token sequences, Free-MoRef achieves improved performance under much lower computing costs in reasoning multiplexed context length, demonstrating strong efficiency and effectiveness. Experiments on VideoMME, MLVU, LongVideoBench show that Free-MoRef achieves full perception of 2$\times$ to 8$\times$ longer input frames without compression on a single A100 GPU while keeping instant responses, thereby bringing significant performance gains, even surpassing dedicatedly trained long-video-MLLMs. Codes will be available.
Chat is not available.
Successful Page Load