Skeleton Motion Words for Unsupervised Skeleton-based Temporal Action Segmentation
{kind=link}
Abstract
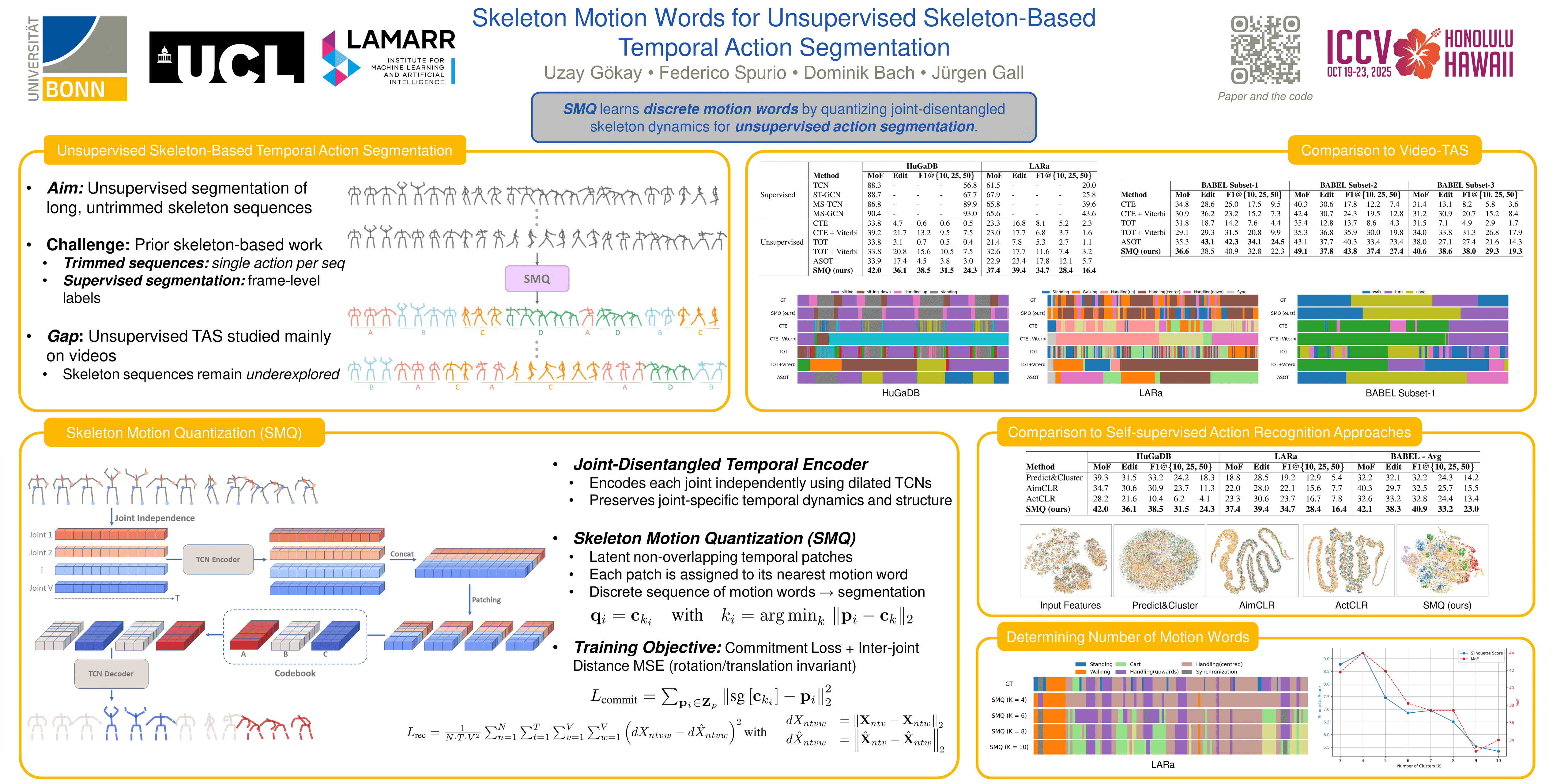
Current state-of-the-art methods for skeleton-based temporal action segmentation are fully supervised and require annotated data, which is expensive to collect. In contrast, existing unsupervised temporal action segmentation methods have focused primarily on video data, while skeleton sequences remain underexplored, despite their relevance to real-world applications, robustness, and privacy-preserving nature. In this paper, we propose a novel approach for unsupervised skeleton-based temporal action segmentation. Our method utilizes a sequence-to-sequence temporal autoencoder that keeps the information of the different joints disentangled in the embedding space. The latent representation is then segmented into non-overlapping patches and quantized to obtain distinctive skeleton motion words, driving the discovery of semantically meaningful action clusters. We thoroughly evaluate our model on three widely used skeleton-based datasets, namely HuGaDB, LARa, and BABEL. Our results demonstrate that SMQ outperforms the current state-of-the-art unsupervised temporal action segmentation methods.