Towards Higher Effective Rank in Parameter-Efficient Fine-tuning using Khatri-Rao Product
{kind=link}
Abstract
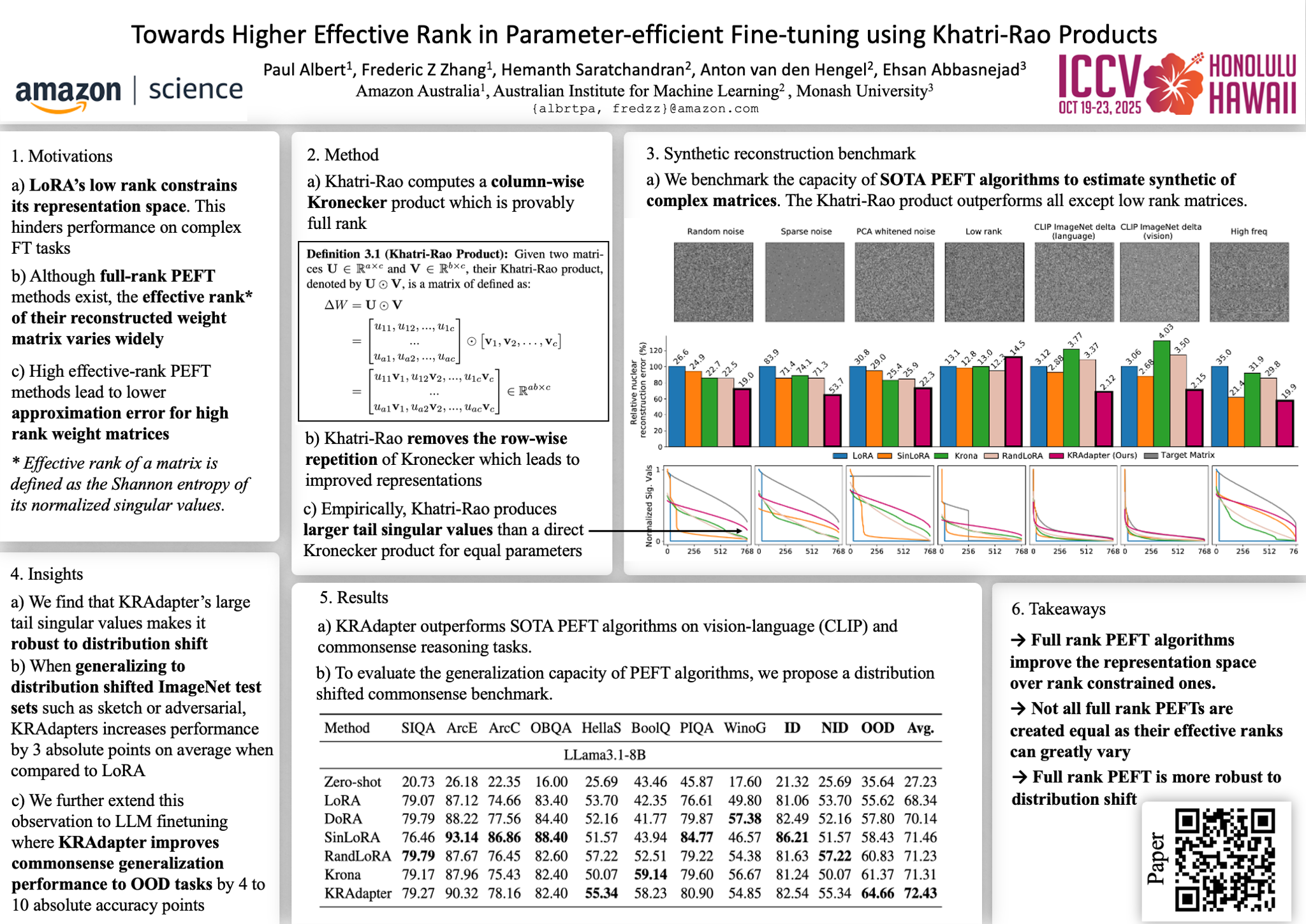
Parameter-efficient fine-tuning (PEFT) has become a standard for adapting large pre-trained models. While low-rank adaptation (LoRA) has achieved notable success, recent studies highlight its limitations when compared to full-rank variants, particularly when scaling to demanding tasks such as vision-language classification or common-sense reasoning.We propose to quantitavely compare full and rank-restricted PEFT methods using a spectrum-controlled matrix approximation benchmark. Our results validate LoRA's rank limitations when approximating matrix presenting highly decorrelated or high frequency features. We further show that full-rank methods can reduce LoRA's approximation error on these matrix types for an equal parameter count.Our evaluation then extends beyond synthetic tasks where we observe that LoRA's restricted work subspace can produce high norm updates, leading to over-fitting and poor out-of-distribution generalization. We address these limits by introducing KRAdapter, a novel PEFT algorithms that uses properties of the Kathri-Rao matrix product to produce weight matrices of higher effective rank and lower norm than related PEFT algorithms.We show the performance improvements of KRAdapter on vision-language models up to 1B parameters and 8B %32Bfor LLMs where we report from 20 to 25 points of accuracy improvements over LoRA when reasoning on commonsense tasks unseen during training. Crucially, KRAdapter maintains the favorable training speed and memory efficiency of LoRA, making it a practical and robust alternative to fine-tune billion-scale parameter models. Code for reproducing toy experiments is available in the supplementary and will be released upon acceptance.