What You Have is What You Track: Adaptive and Robust Multimodal Tracking
{kind=link}
Abstract
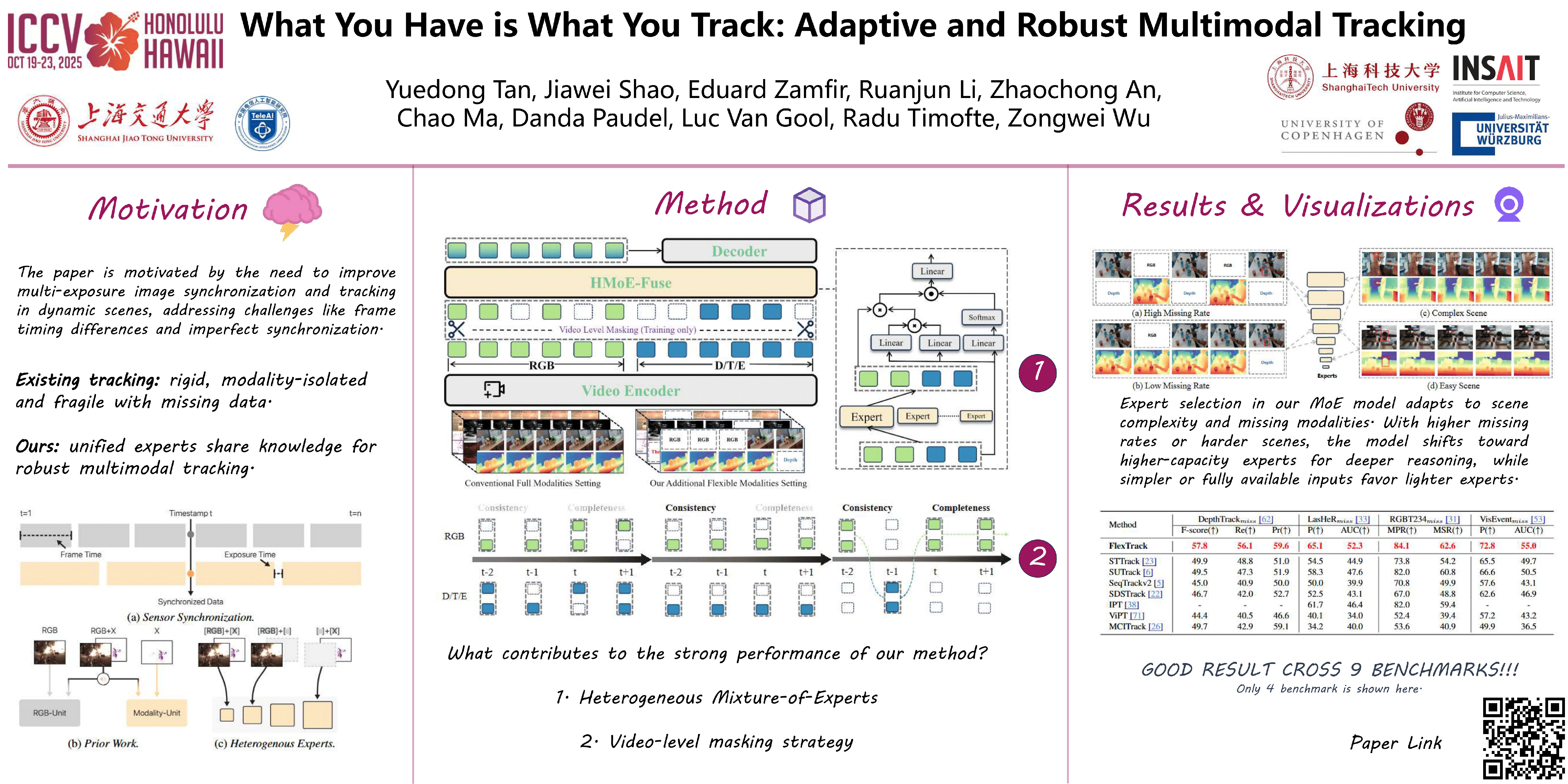
Multimodal data is known to be helpful for visual tracking by improving robustness to appearance variations. However, sensor synchronization challenges often compromise data availability, particularly in video settings where shortages can be temporal. Despite its importance, this area remains underexplored. In this paper, we present the first comprehensive study on tracker performance with temporally incomplete multimodal data. Unsurprisingly, under such a circumstance, existing trackers exhibit significant performance degradation, as their rigid architectures lack the adaptability needed to effectively handle missing modalities.To address these limitations, we propose a flexible framework for robust multimodal tracking. We venture that a tracker should dynamically activate computational units based on missing data rates. This is achieved through a novel Heterogeneous Mixture-of-Experts fusion mechanism with adaptive complexity, coupled with a video-level masking strategy that ensures both temporal consistency and spatial completeness — critical for effective video tracking. Surprisingly, our model not only adapts to varying missing rates but also adjusts to scene complexity. Extensive experiments show that our model achieves SOTA performance across 9 benchmarks, excelling in both conventional complete and missing modality settings. The code and benchmark will be made publicly available.