Knowledge Transfer from Interaction Learning
Yilin Gao ⋅ Kangyi Chen ⋅ Zhongxing Peng ⋅ Hengjie Lu ⋅ Shugong Xu
2025 Poster
{kind=link}
Abstract
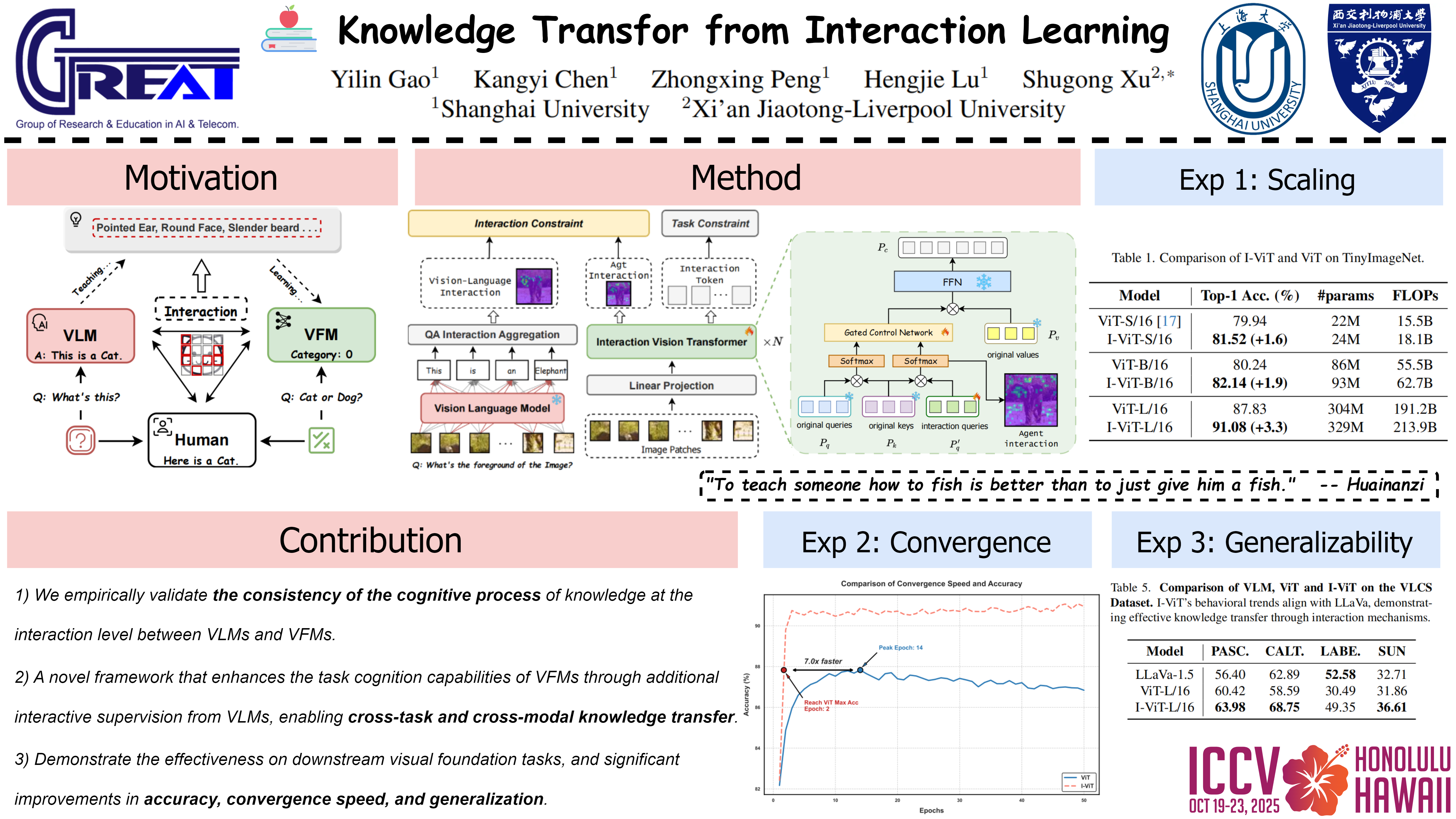
Current visual foundation models (VFMs) face a fundamental limitation in transferring knowledge from vision language models (VLMs): while VLMs excel at modeling cross-modal interactions through unified representation spaces, existing VFMs predominantly adopt \textit{result-oriented} paradigms that neglect the underlying interaction processes. This representational discrepancy leads to suboptimal knowledge transfer and limited generalization capabilities across vision tasks.We propose Learning from Interactions, a cognitive-inspired framework that bridges this gap by explicitly modeling interactions during visual understanding. Our key insight is that preserving the interaction dynamics captured by VLMs -- rather than just their final representations -- enables more effective knowledge transfer to downstream VFMs. The technical core involves two innovations: (1) \textit{Interaction Queries} that maintain persistent relationships across network layers, and (2) interaction-based supervision derived from pre-trained VLMs' cross-modal attention patterns.Comprehensive experiments demonstrate consistent improvements across multiple benchmarks: achieving $\sim$3.3\% and $+$1.6 mAP/$+$2.4 $AP^{mask}$ absolute gains on TinyImageNet classification and COCO detection/segmentation respectively, with minimal parameter overhead and faster convergence (7$\times$ speedup). The framework particularly excels in cross-domain scenarios, delivering $\sim$2.4\% and $\sim$9.3\% zero-shot improvements on PACS and VLCS. Human evaluations confirm our approach's cognitive alignment, outperforming result-oriented methods by 2.7$\times$ in semantic consistency metrics.
Chat is not available.
Successful Page Load