Efficient Fine-Tuning of Large Models via Nested Low-Rank Adaptation
{kind=link}
Abstract
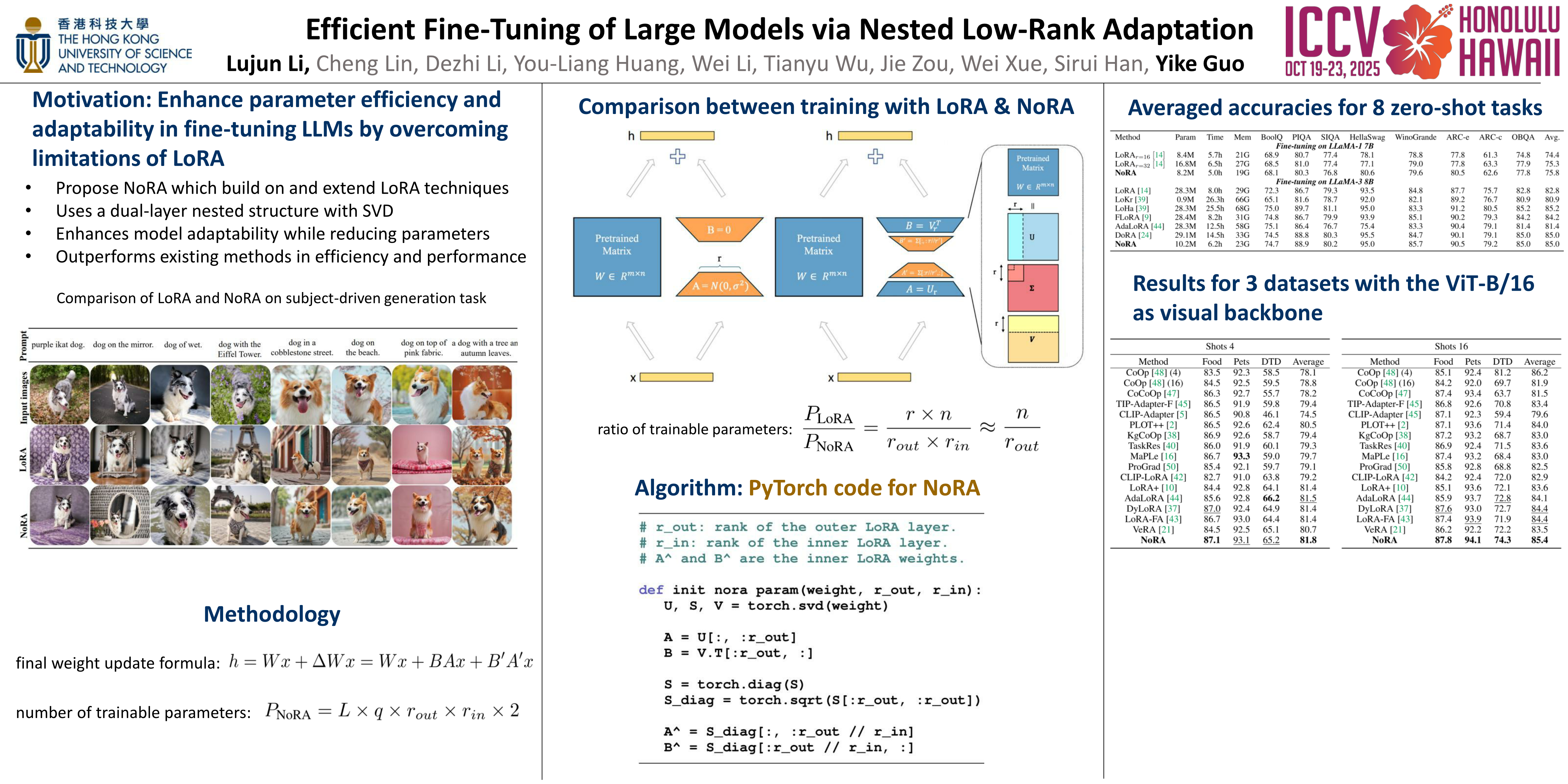
Low-Rank Adaptation (LoRA) has become a popular paradigm for fine-tuning large models, but it still necessitates a substantial number of training parameters. To address this issue, we first conduct comprehensive empirical studies on parameter-efficient LoRA structure. Then, we establish design guidelines that emphasize the use of serial structures, optimal placements, and nested LoRA. Based on these insights, we present NoRA, a nested parameter-efficient LoRA structure that revolutionizes the initialization and fine-tuning of projection matrices. Our NoRA's innovative approach involves freezing outer layer LoRA weights and employing a serial inner layer design, enabling precise task-specific adaptations while maintaining compact training parameters. In addition, we propose an activation-aware Singular Value Decomposition (AwSVD) that adjusts the weight matrices based on activation distributions for initialization of outer layer LoRA weights. This schema enhances decomposition accuracy and mitigates computational errors. Extensive evaluations across multiple large models demonstrate that NoRA outperforms state-of-the-art LoRA variants, achieving significant improvements in performance-efficiency trade-off on visual few-shot tasks, visual instruction tuning and subject-driven generation. Codes are available in the supplementary materials.