LLaVA-KD: A Framework of Distilling Multimodal Large Language Models
Yuxuan Cai ⋅ Jiangning Zhang ⋅ Haoyang He ⋅ Xinwei He ⋅ Ao Tong ⋅ Zhenye Gan ⋅ Chengjie Wang ⋅ Zhucun Xue ⋅ Yong Liu ⋅ Xiang Bai
2025 Poster
{kind=link}
Abstract
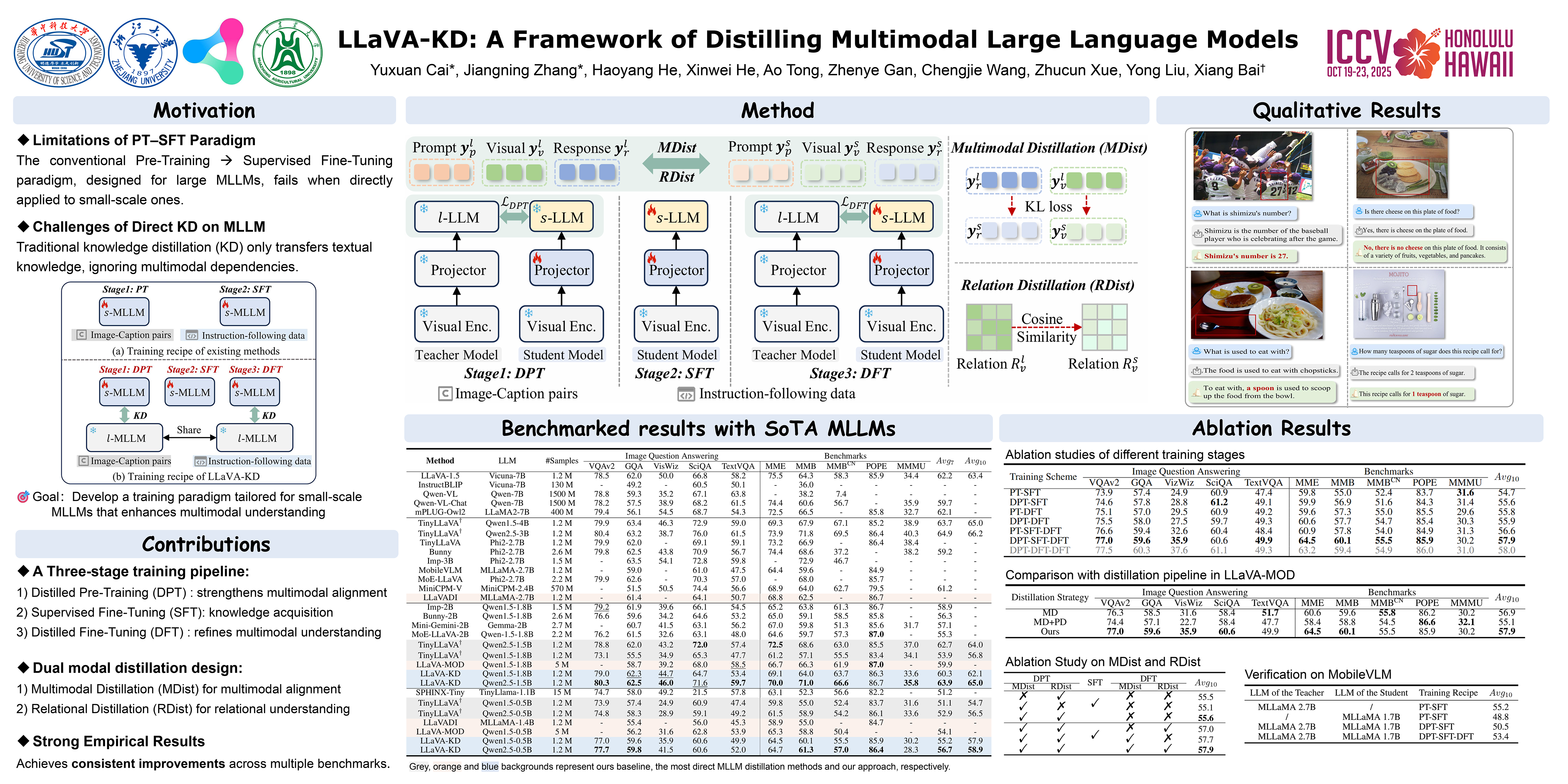
The success of Large Language Models (LLMs) has inspired the development of Multimodal Large Language Models (MLLMs) for unified understanding of vision and language. However, the increasing model size and computational complexity of large-scale MLLMs ($l$-MLLMs) limit their use in resource-constrained scenarios. Although small-scale MLLMs ($s$-MLLMs) are designed to reduce computational costs, they typically suffer from performance degradation.To mitigate this limitation, we propose a novel \method~framework to transfer knowledge from $l$-MLLMs to $s$-MLLMs. Specifically, we introduce Multimodal Distillation (MDist) to transfer teacher model's robust representations across both visual and linguistic modalities, and Relation Distillation (RDist) to transfer teacher model's ability to capture visual token relationships.Additionally, we propose a three-stage training scheme to fully exploit the potential of the proposed distillation strategy: \textit{1)} Distilled Pre-Training to strengthen the alignment between visual-linguistic representations in $s$-MLLMs, \textit{2)} Supervised Fine-Tuning to equip the $s$-MLLMs with multimodal understanding capacity, and \textit{3)} Distilled Fine-Tuning to refine $s$-MLLM's knowledge.Our approach significantly improves $s$-MLLMs performance without altering the model architecture. Extensive experiments and ablation studies validate the effectiveness of each proposed component. Code will be available.
Chat is not available.
Successful Page Load