Benchmarking Multimodal Large Language Models Against Image Corruptions
{kind=link}
Abstract
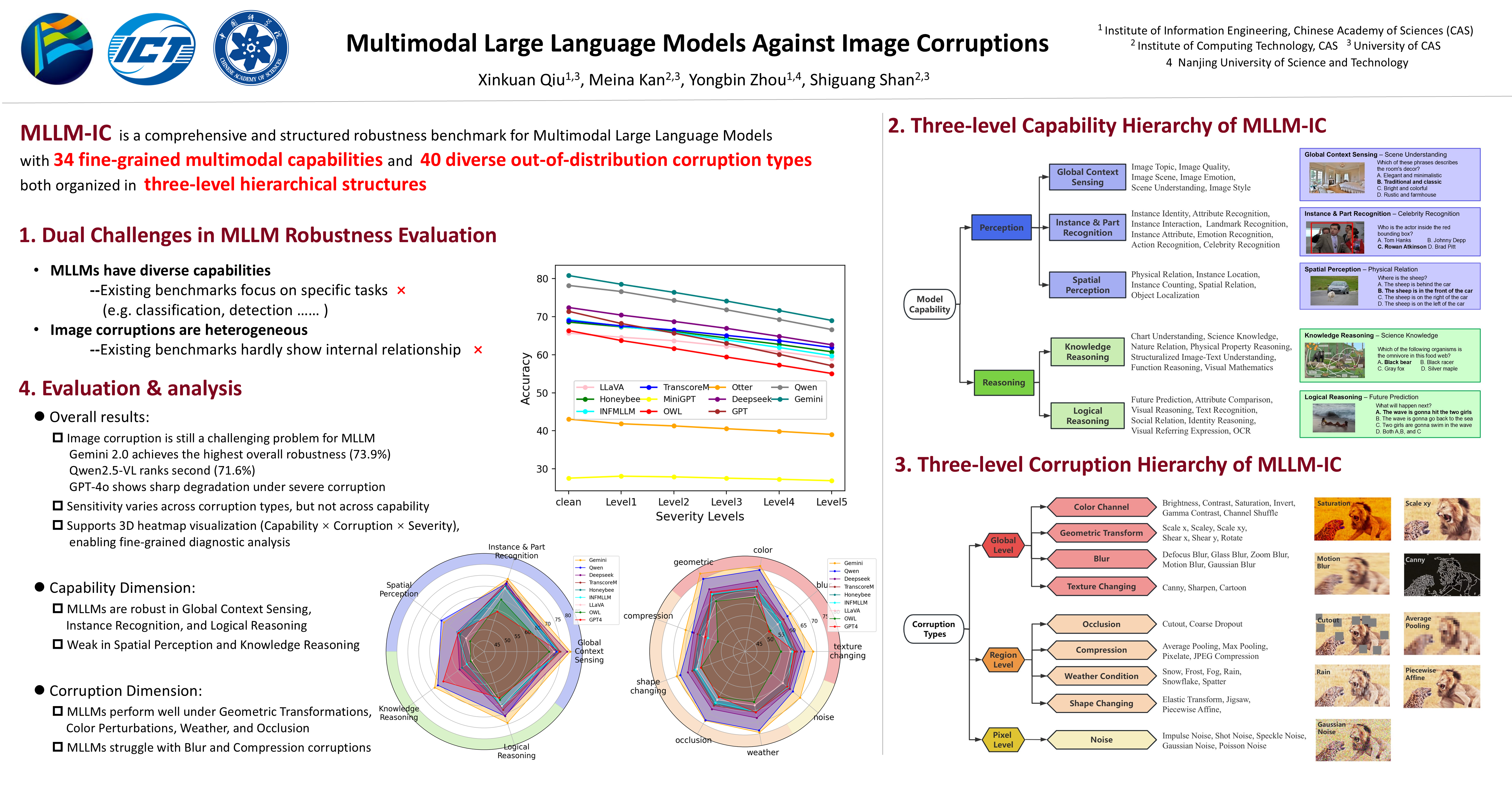
Multimodal Large Language Models (MLLMs) have made significant strides in visual and language tasks. However, despite their impressive performance on standard datasets, these models encounter considerable robustness challenges when processing corrupted images, raising concerns about their reliability in safety-critical applications. To address this issue, we introduce the MLLM-IC benchmark, specifically designed to assess the performance of MLLMs under image corruption scenarios. MLLM-IC offers a more comprehensive evaluation of corruption robustness compared to existing benchmarks, enabling a multi-dimensional assessment of various MLLM capabilities across a broad range of corruption types. It includes 40 distinct corruption types and 34 low-level multimodal capabilities, each organized into a three-level hierarchical structure. Notably, it is the first corruption robustness benchmark designed to facilitate the evaluation of fine-grained MLLM capabilities. We further evaluate several prominent MLLMs and derive valuable insights into their characteristics. We believe the MLLM-IC benchmark will provide crucial insights into the robustness of MLLMs in handling corrupted images and contribute to the development of more resilient MLLMs.