Test-Time Retrieval-Augmented Adaptation for Vision-Language Models
{kind=link}
Abstract
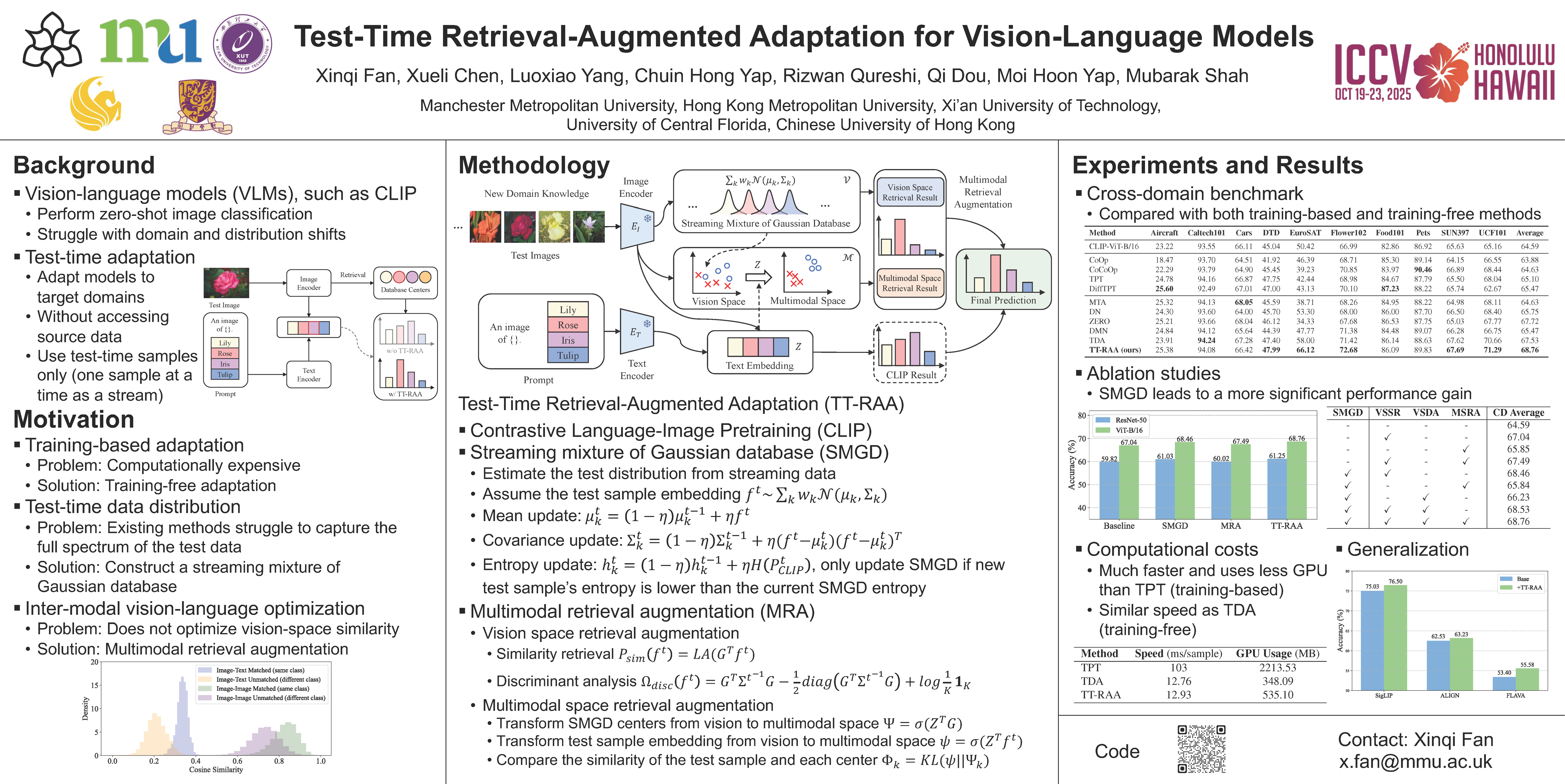
Vision-language models (VLMs) have shown promise in test-time adaptation tasks due to their remarkable capabilities in understanding and reasoning about visual content through natural language descriptions. However, training VLMs typically demands substantial computational resources, and they often struggle to adapt efficiently to new domains or tasks. Additionally, dynamically estimating the test distribution from streaming data at test time remains a significant challenge. In this work, we propose a novel test-time retrieval-augmented adaption (TT-RAA) method that enables VLMs to maintain high performance across diverse visual recognition tasks without the need for task-specific training or large computational overhead. During inference, TT-RAA employs a streaming mixture of Gaussian database (SMGD) to continuously estimate test distributions, requiring minimal storage. Then, TT-RAA retrieves the most relevant information from the SMGD, enhancing the original VLM outputs. A key limitation of CLIP-based VLMs is their inter-modal vision-language optimization, which does not optimize vision-space similarity, leading to larger intra-modal variance. To address this, we propose a multimodal retrieval augmentation module that transforms the SMGD into a unified multimodal space, enabling retrieval that aligns both vision and language modalities. Extensive experiments across both cross-domain and out-of-distribution benchmarks comprising fourteen datasets demonstrate TT-RAA’s superior performance compared to state-of-the-art methods. Ablation studies and hyperparameter analyses further validate the effectiveness of the proposed modules.