Extending Foundational Monocular Depth Estimators to Fisheye Cameras with Calibration Tokens
{kind=link}
Abstract
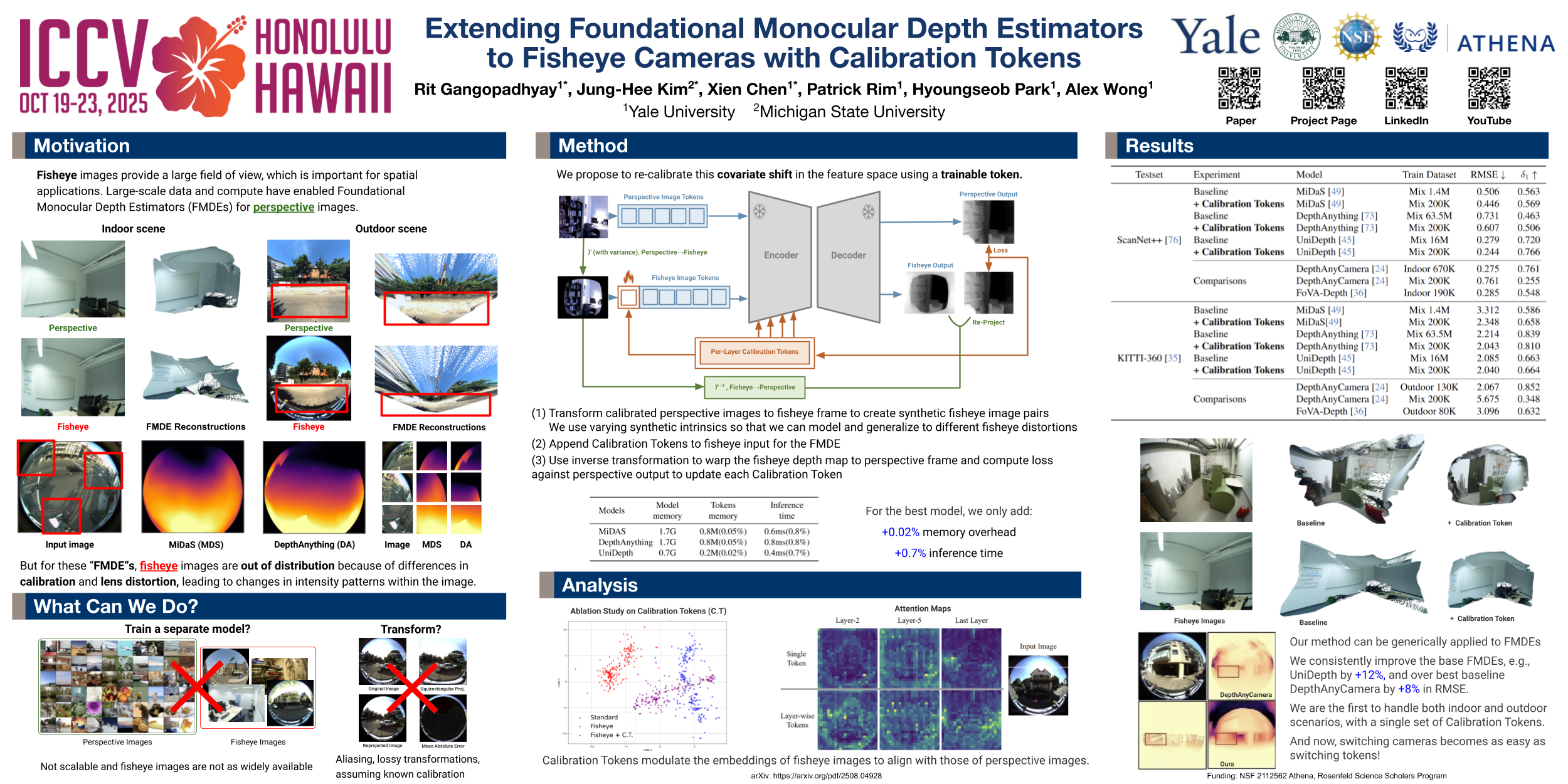
Monocular depth estimation (MDE) has advanced significantly with the introduction of transformer-based foundational vision models. However, their application to fisheye images, widely used in robotics, security systems, autonomous vehicles, and augmented reality due to their wide field of view, remains challenging due to severe radial distortions and calibration differences. Standard transformer-based models trained on perspective images fail to generalize effectively to fisheye inputs, resulting in poor depth predictions. To address this, we introduce \emph{calibration tokens}, a lightweight, token-based adaptation method that allows perspective-trained foundational models to handle fisheye distortions without retraining or fine-tuning the entire network. Calibration tokens learn to realign distorted fisheye features with the perspective latent distribution in a self-supervised manner using a novel inverse warping consistency loss. This training approach leverages existing perspective image datasets and pre-trained foundational models without requiring labeled fisheye images. Experiments demonstrate that our calibration tokens improve performance on real-world fisheye datasets for monocular depth estimation tasks, surpassing baselines while maintaining computational efficiency and inference-time simplicity.