Leveraging Debiased Cross-modal Attention Maps and Code-based Reasoning for Zero-shot Referring Expression Comprehension
{kind=link}
Abstract
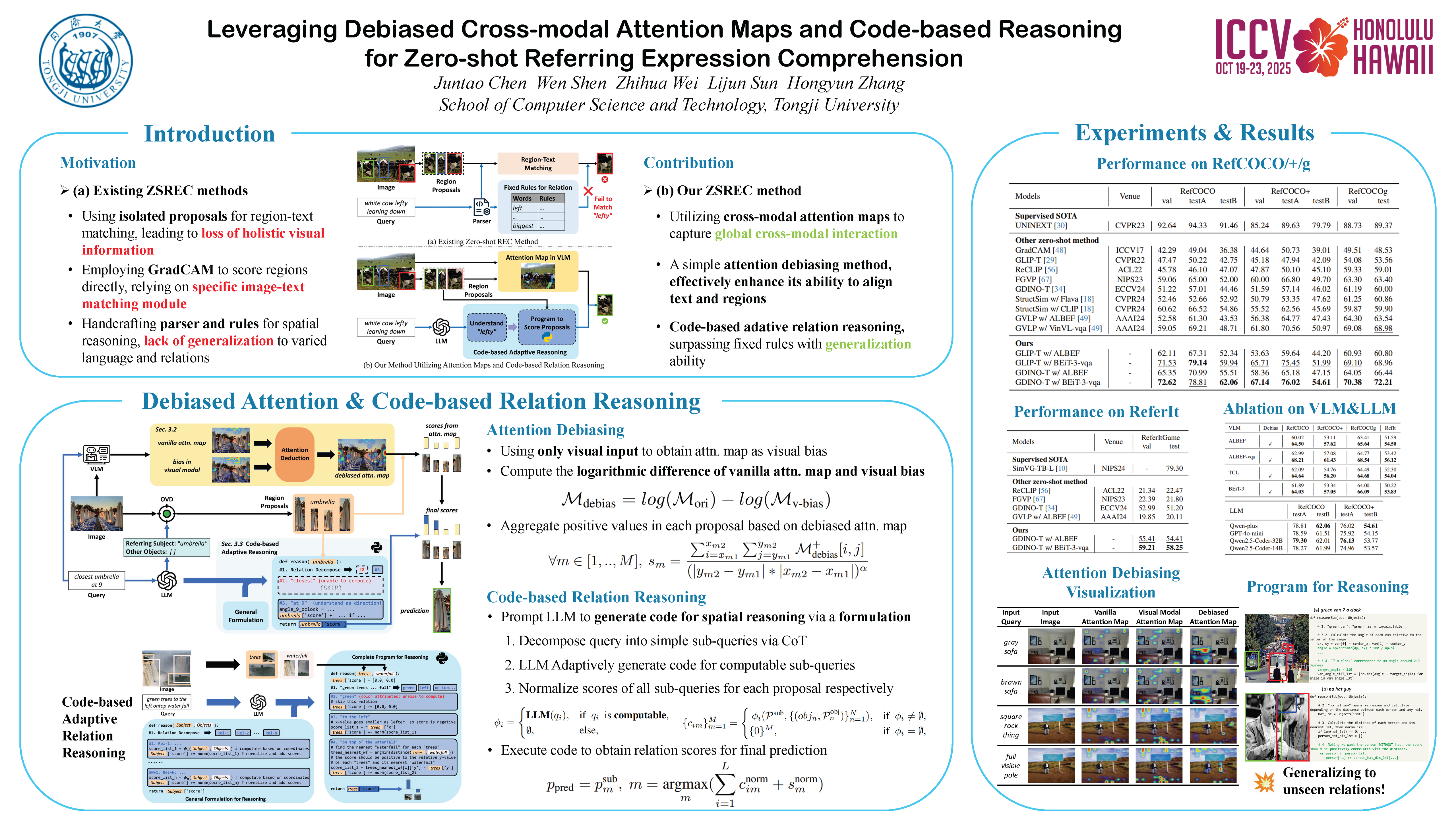
Zero-shot Referring Expression Comprehension (REC) aims at locating an object described by a natural language query without training on task-specific datasets. Current approaches often utilize Vision-Language Models (VLMs) to perform region-text matching based on region proposals. However, this may downgrade their performance since VLMs often fail in relation understanding and isolated proposals inevitably lack global image context. To tackle these challenges, we first design a general formulation for code-based relation reasoning. It instructs Large Language Models (LLMs) to decompose complex relations and adaptively implement code for spatial and relation computation. Moreover, we directly extract region-text relevance from cross-modal attention maps in VLMs. Observing the inherent bias in VLMs, we further develop a simple yet effective bias deduction method, which enhances attention maps' capability to align text with the corresponding regions. Experimental results on four representative datasets demonstrate the SOTA performance of our method. On the RefCOCO dataset centered on spatial understanding, our method gets an average improvement of 10\% over the previous zero-shot SOTA. Code will be released as our paper is accepted.