Memory-Efficient Generative Models via Product Quantization
Jie Shao ⋅ Hanxiao Zhang ⋅ Hao Yu ⋅ Jianxin Wu
2025 Poster
{kind=link}
Abstract
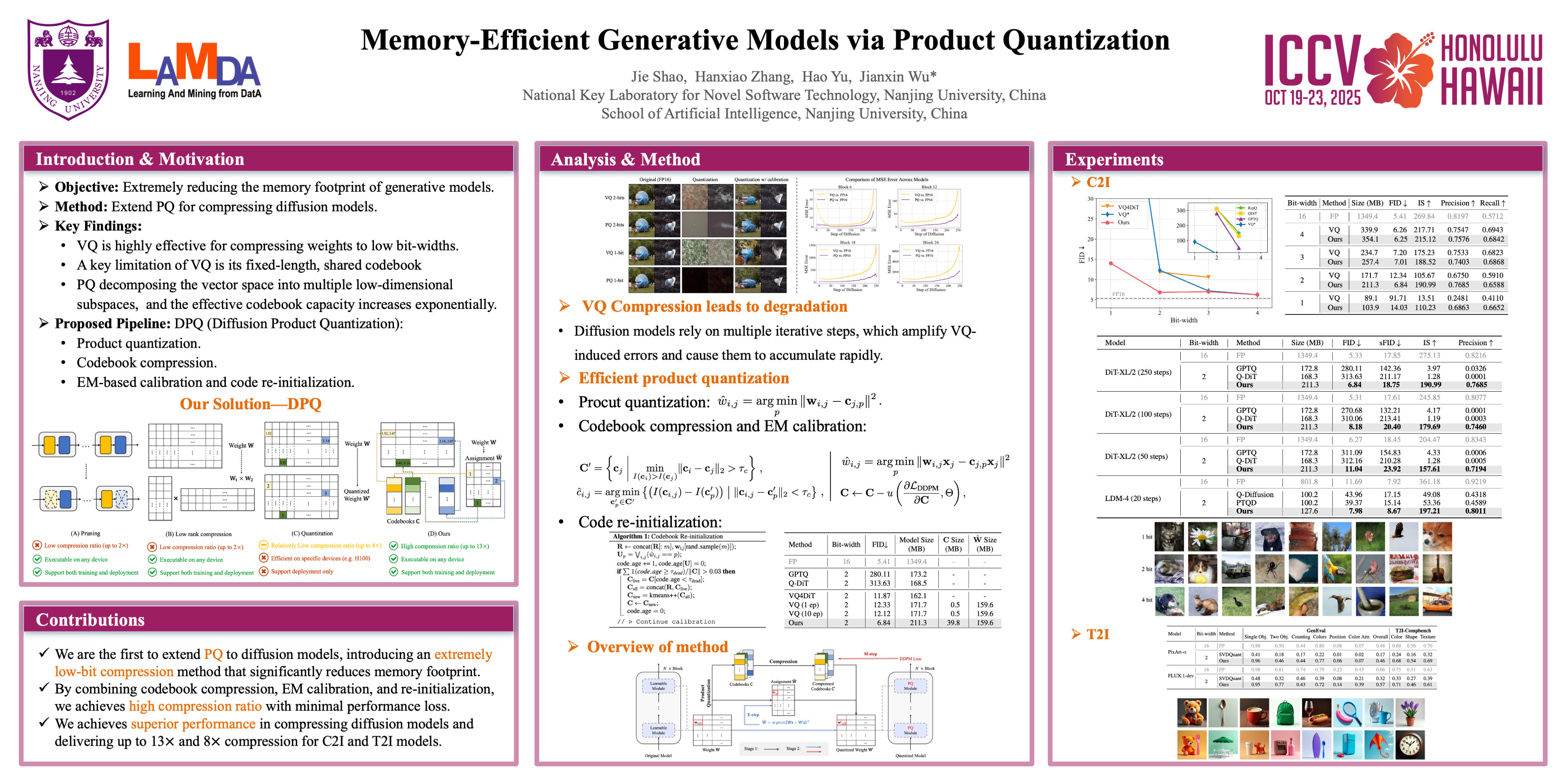
The rapid progress in generative models has significantly enhanced the quality of image generation. However, as these models grow larger, deploying and fine-tuning them becomes increasingly challenging. While conventional quantization techniques help reduce model size, they struggle to achieve high compression rates without significant performance loss. As a result, memory footprint remains a critical challenge for generative models. In this work, we explore the extreme compression of generative models through codebook quantization, drastically reducing model size while maintaining performance. We extend product quantization for model compression, significantly increasing codebook capacity, which is crucial for preserving the generative quality of diffusion models. We also introduce a codebook compression method for memory efficiency. To further minimize performance degradation, we develop EM calibration with re-initialization that optimizes both assignments and centroids. By compressing the model to as low as 1 bit (achieving a 13$\times$ reduction in model size), we obtain a highly compact generative model with remarkable image quality. Extensive experiments on ImageNet demonstrate the superiority of our method over existing techniques. Furthermore, we validate its effectiveness across various generation, language and 3D tasks, highlighting its broad applicability and robust performance.
Chat is not available.
Successful Page Load