Dynamic Multi-Layer Null Space Projection for Vision-Language Continual Learning
{kind=link}
Abstract
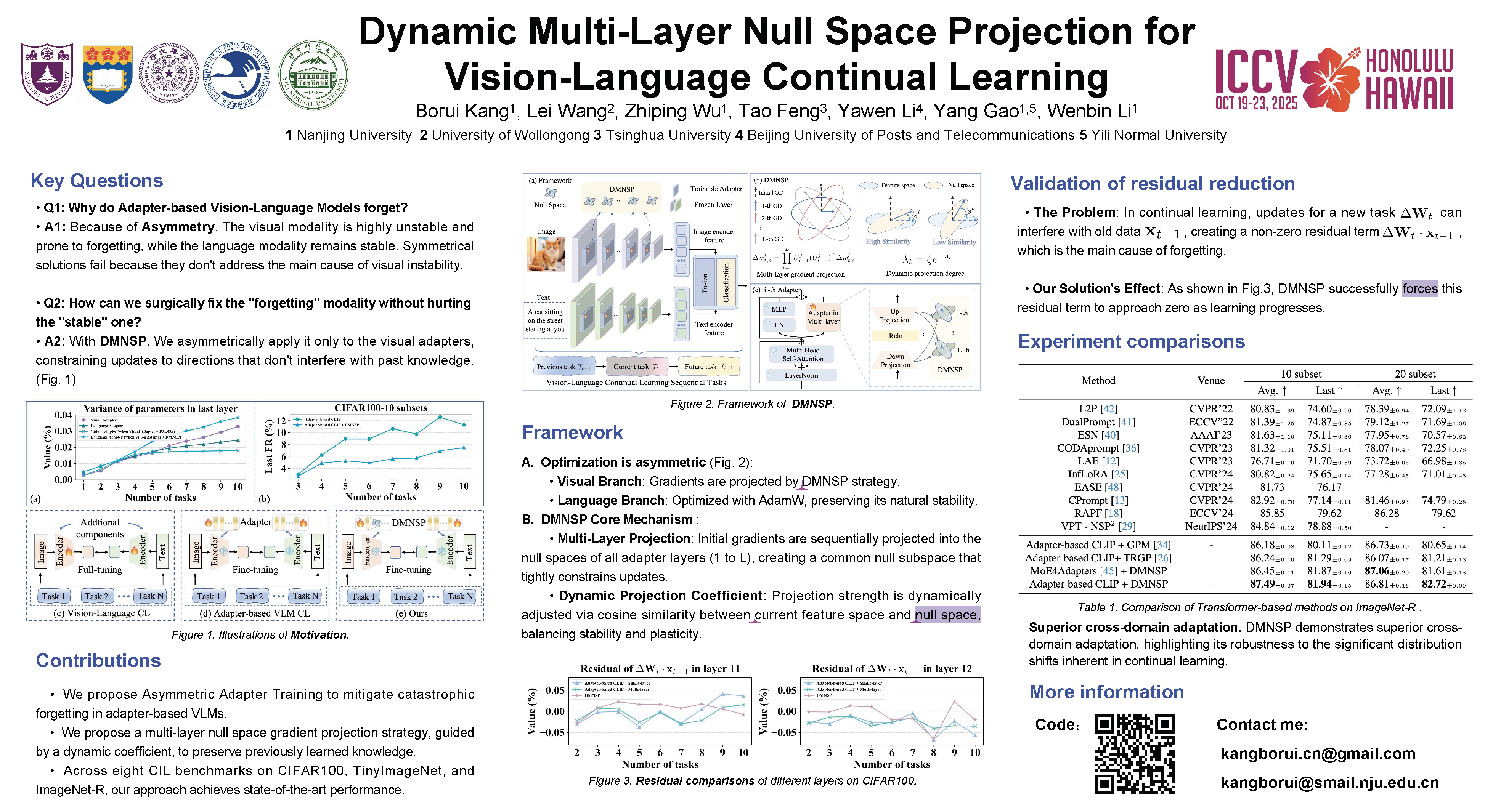
Vision-Language Models (VLM) have emerged as a highly promising approach for Continual Learning (CL) due to their powerful generalized features. While adapter-based VLM can exploit both task-specific and task-agnostic features, current CL methods have largely overlooked the distinct and evolving parameter distributions in visual and language modalities, which are found crucial for effectively mitigating catastrophic forgetting.In this study, we find that the visual modality experiences a broader parameter distribution and greater variance during class increments than the textual modality, leading to higher vulnerability to forgetting.Consequently, we handle the branches of the two modalities asymmetrically. Specifically, we propose a Dynamic Multi-layer Null Space Projection (DMNSP) strategy and apply it only to the visual modality branch, while optimizing the language branch according to the original optimizer. DMNSP can restrict the update of visual parameters within the common subspace of multiple null spaces, further limiting the impact of non-zero residual terms. Simultaneously, combined with a dynamic projection coefficient, we can precisely control the magnitude of gradient projection to the null space, endowing the model with good stability and plasticity.Extensive experiments on TinyImageNet, CIFAR100 and ImageNet-R demonstrate that our method outperforms current approaches in accuracy and knowledge retention, setting a new standard for state-of-the-art performance in class incremental learning.