Depth AnyEvent: A Cross-Modal Distillation Paradigm for Event-Based Monocular Depth Estimation
{kind=link}
Abstract
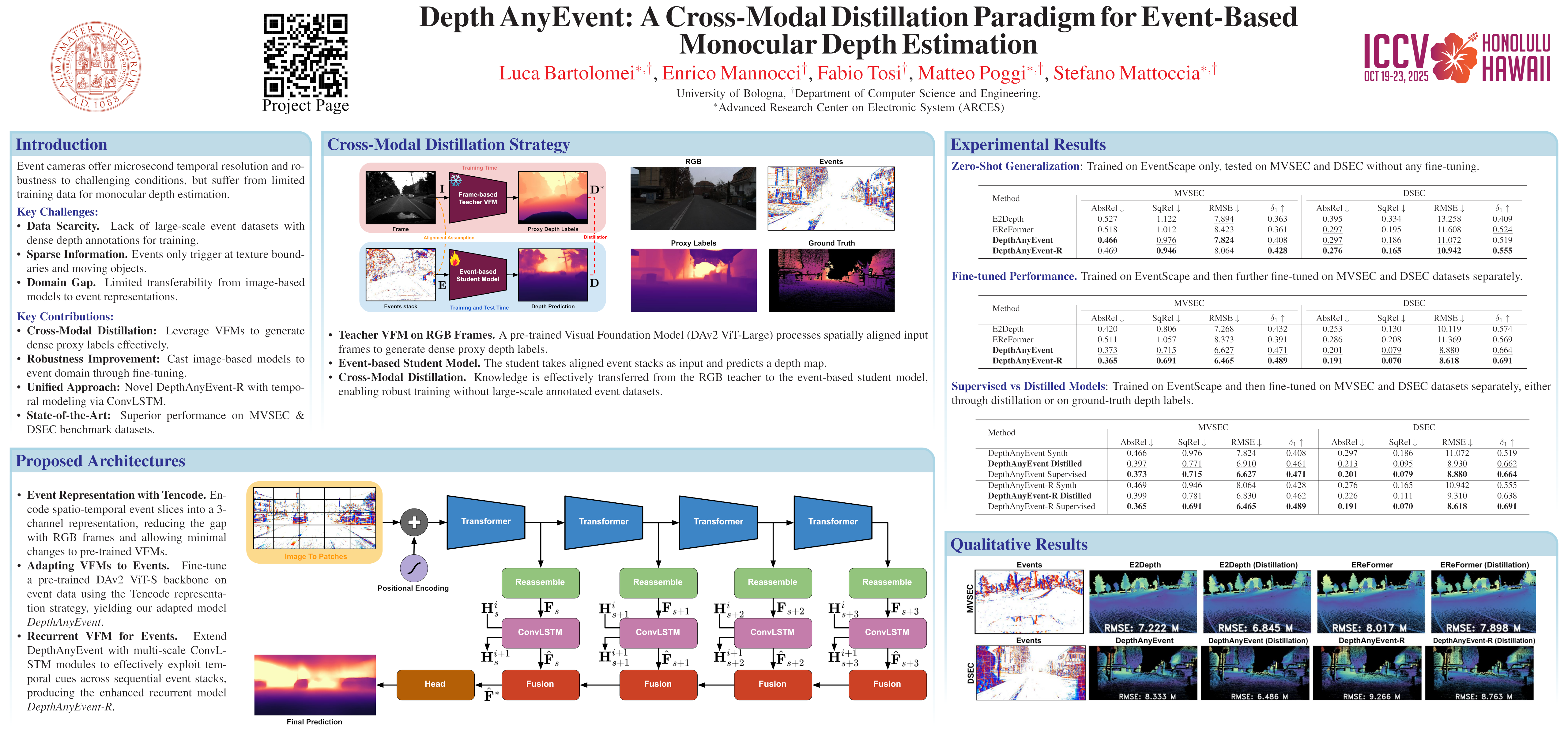
Event cameras capture sparse, high-temporal-resolution visual information, making them particularly suitable for challenging environments with high-speed motion and strongly varying lighting conditions. However, the lack of large datasets with dense ground-truth depth annotations hinders learning-based monocular depth estimation from event data. To address this limitation, we propose a cross-modal distillation paradigm to generate dense proxy labels leveraging a Vision Foundation Model (VFM). Our strategy requires an event stream spatially aligned with RGB frames, a simple setup even available off-the-shelf, and exploits the robustness of large-scale VFMs.Additionally, we propose to adapt VFMs, either a vanilla one like Depth Anything v2 (DAv2), or deriving from it a novel recurrent architecture to infer depth from monocular event cameras. We evaluate our approach using synthetic and real-world datasets, demonstrating that i) our cross-modal paradigm achieves competitive performance compared to fully supervised methods without requiring expensive depth annotations, and ii) our VFM-based models achieve state-of-the-art performance