Gaze-Language Alignment for Zero-Shot Prediction of Visual Search Targets from Human Gaze Scanpaths
{kind=link}
Abstract
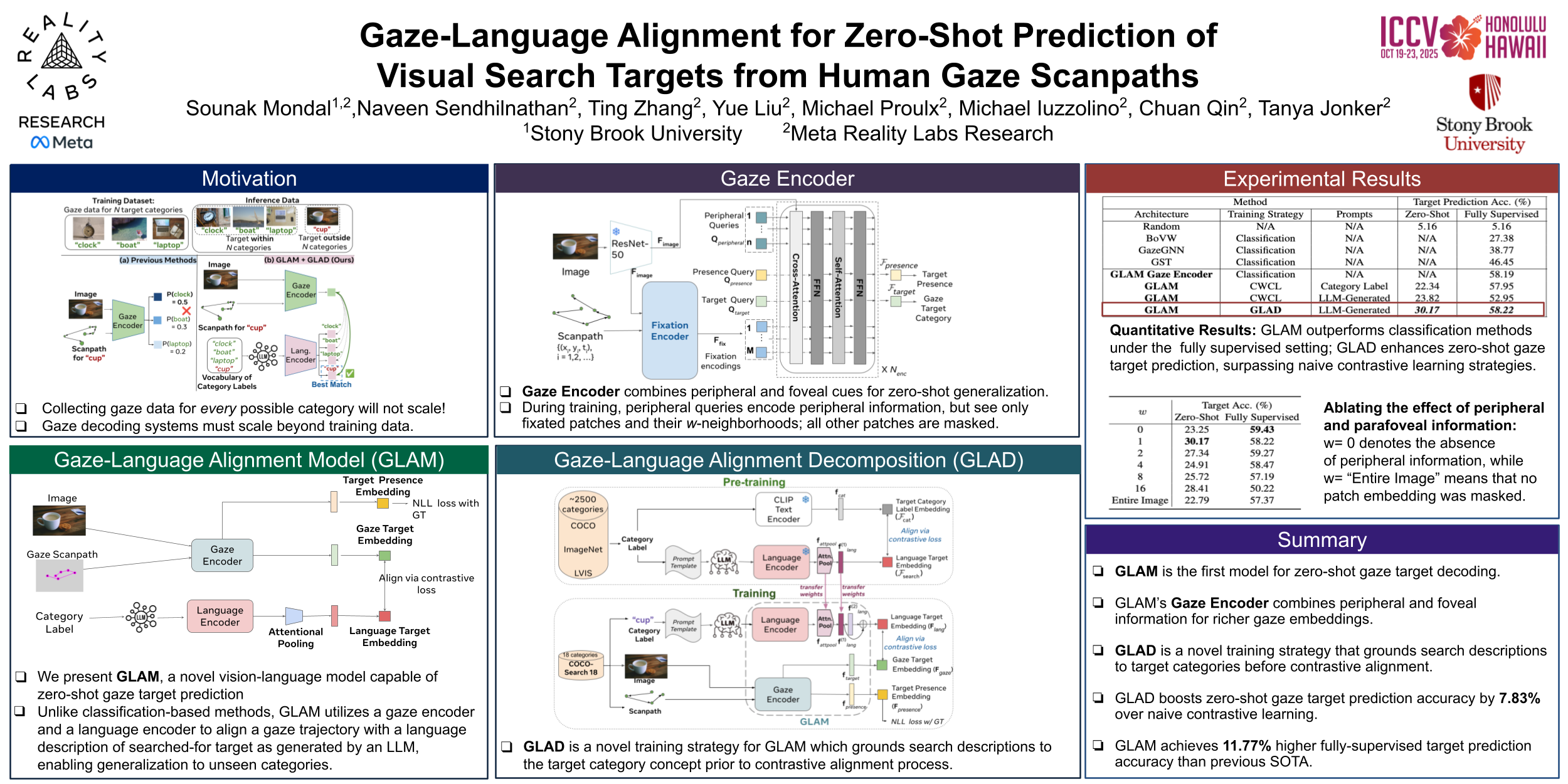
Decoding human intent from eye gaze during a visual search task has become an increasingly important capability within augmented and virtual reality systems. However, gaze target prediction models used within such systems are constrained by the predefined target categories found within available gaze data, limiting their generalizability to novel categories and their usefulness within real-world, interactive systems. In this work, we present the Gaze-Language Alignment Model (GLAM), a vision-language model that can generalize gaze target predictions to novel categories of search targets lacking gaze annotation. To do so, GLAM uses a novel gaze encoder to encode foveal and peripheral information of a gaze scanpath. The resultant gaze embeddings are aligned with language embeddings of large language model-generated search descriptions for associated target categories using a novel contrastive learning strategy called Gaze-Language Alignment Decomposition (GLAD). When used to train GLAM in a zero-shot setup, GLAD surpassed naive contrastive learning strategies by nearly one-third in target prediction accuracy, even outperforming a fully supervised baseline. Moreover, in a fully supervised setup, GLAM outperformed previous methods in target prediction accuracy, regardless of the training strategy used.