Flow to the Mode: Mode-Seeking Diffusion Autoencoders for State-of-the-Art Image Tokenization
{kind=link}
Abstract
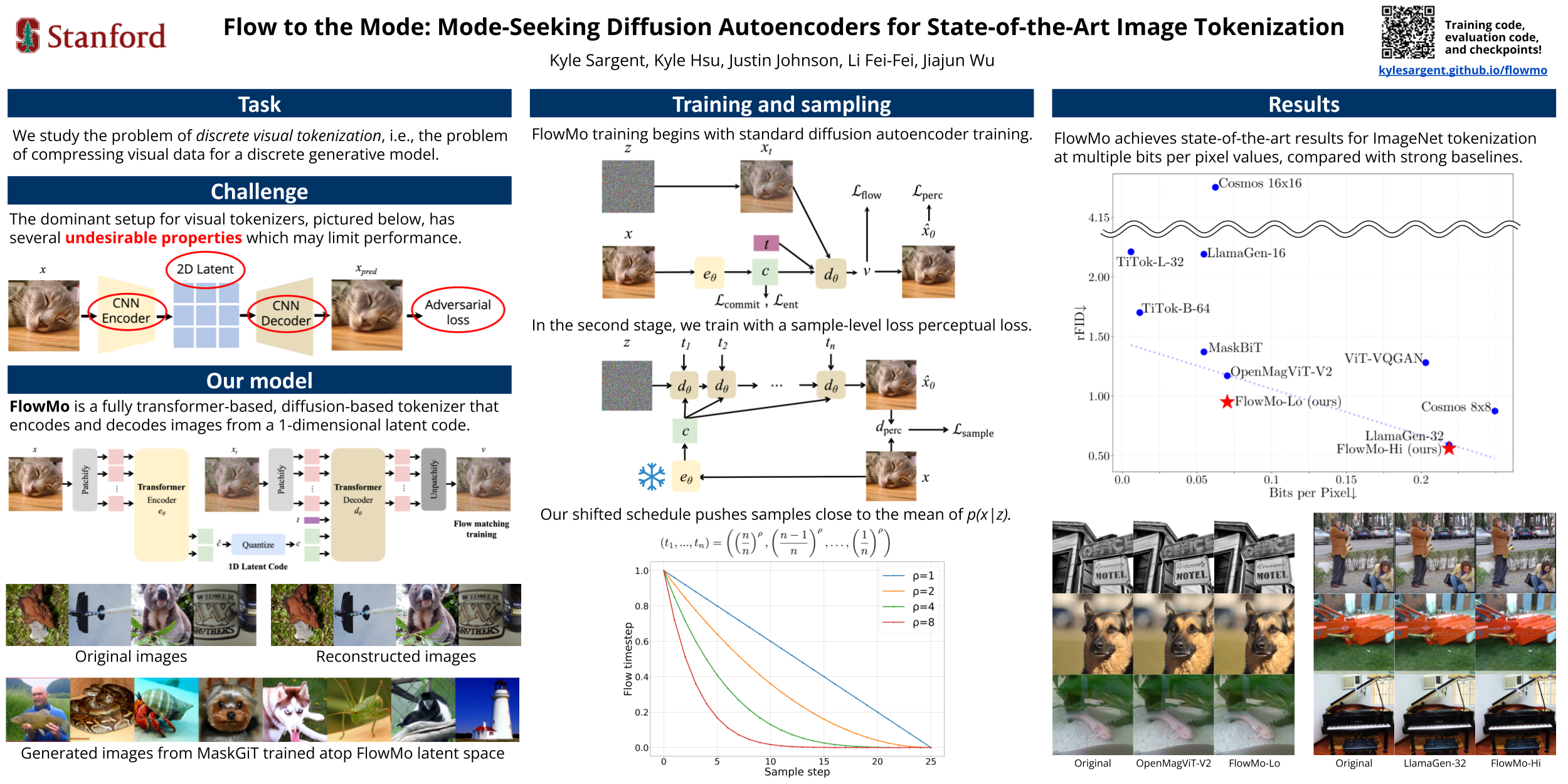
Since the advent of popular visual generation frameworks like VQGAN and Latent Diffusion Models, state-of-the-art image generation systems have generally been two-stage systems that first tokenize or compress visual data into a lower-dimensional latent space before learning a generative model. Tokenizer training typically follows a standard recipe in which images are compressed and reconstructed subject to a combination of MSE, perceptual, and adversarial losses. Diffusion autoencoders have been proposed in prior work as a way to learn end-to-end perceptually-oriented image compression, but have not yet shown state-of-the-art performance on the competitive task of ImageNet-1K reconstruction. In this work, we propose FlowMo, a transformer-based diffusion autoencoder. FlowMo achieves a new state-of-the-art for image tokenization at multiple bitrates. We achieve this without using convolutions, adversarial losses, spatially-aligned 2D latent codes, or distilling from other tokenizers. Our key insight is that FlowMo training should be broken into a mode-matching pre-training stage and a mode-seeking post-training stage. We conduct extensive analysis and ablations, and we additionally train generative models atop the FlowMo tokenizer and verify the performance. We will release our code and model checkpoints upon acceptance.