Rethinking Cross-Modal Interaction in Multimodal Diffusion Transformers
{kind=link}
Abstract
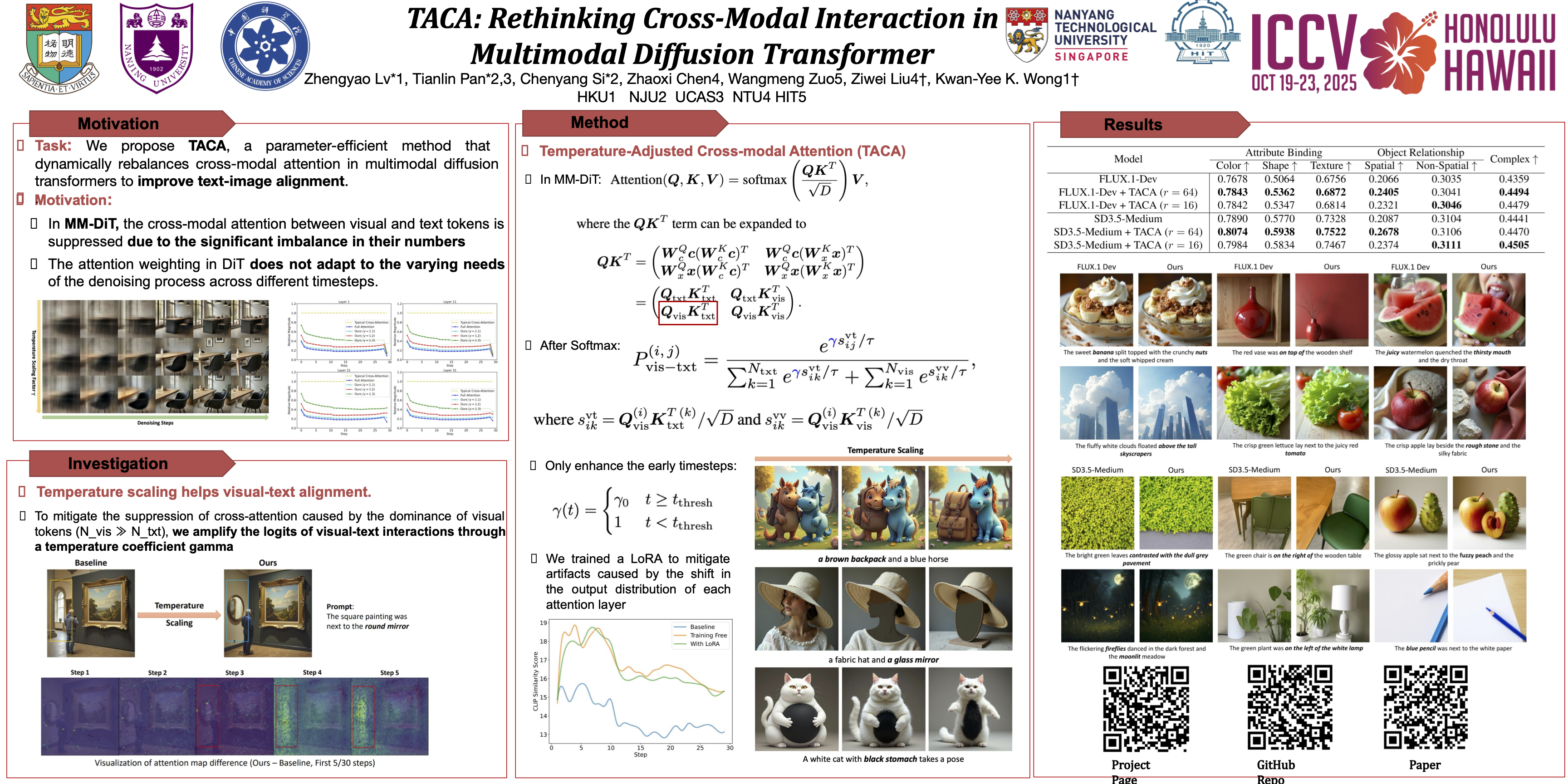
Multimodal Diffusion Transformers (MM-DiTs) have achieved remarkable progress in text-driven visual generation. However, even state-of-the-art MM-DiT models like FLUX struggle with achieving precise alignment between text prompts and generated content. We identify two key issues in the attention mechanism of MM-DiT, namely 1) the suppression of cross-modal attention due to token imbalance between visual and textual modalities and 2) the lack of timestep-aware attention weighting, which hinder the alignment. To address these issues, we propose \textbf{Temperature-Adjusted Cross-modal Attention (TACA)}, a parameter-efficient method that dynamically rebalances multimodal interactions through temperature scaling and timestep-dependent adjustment. When combined with LoRA fine-tuning, TACA significantly enhances text-image alignment on the T2I-CompBench benchmark with minimal computational overhead. We tested TACA on state-of-the-art models like FLUX and SD3.5, demonstrating its ability to improve image-text alignment in terms of object appearance, attribute binding, and spatial relationships. Our findings highlight the importance of balancing cross-modal attention in improving semantic fidelity in text-to-image diffusion models. Our code will be made publicly available.