H3R: Hybrid Multi-view Correspondence for Generalizable 3D Reconstruction
{kind=link}
Abstract
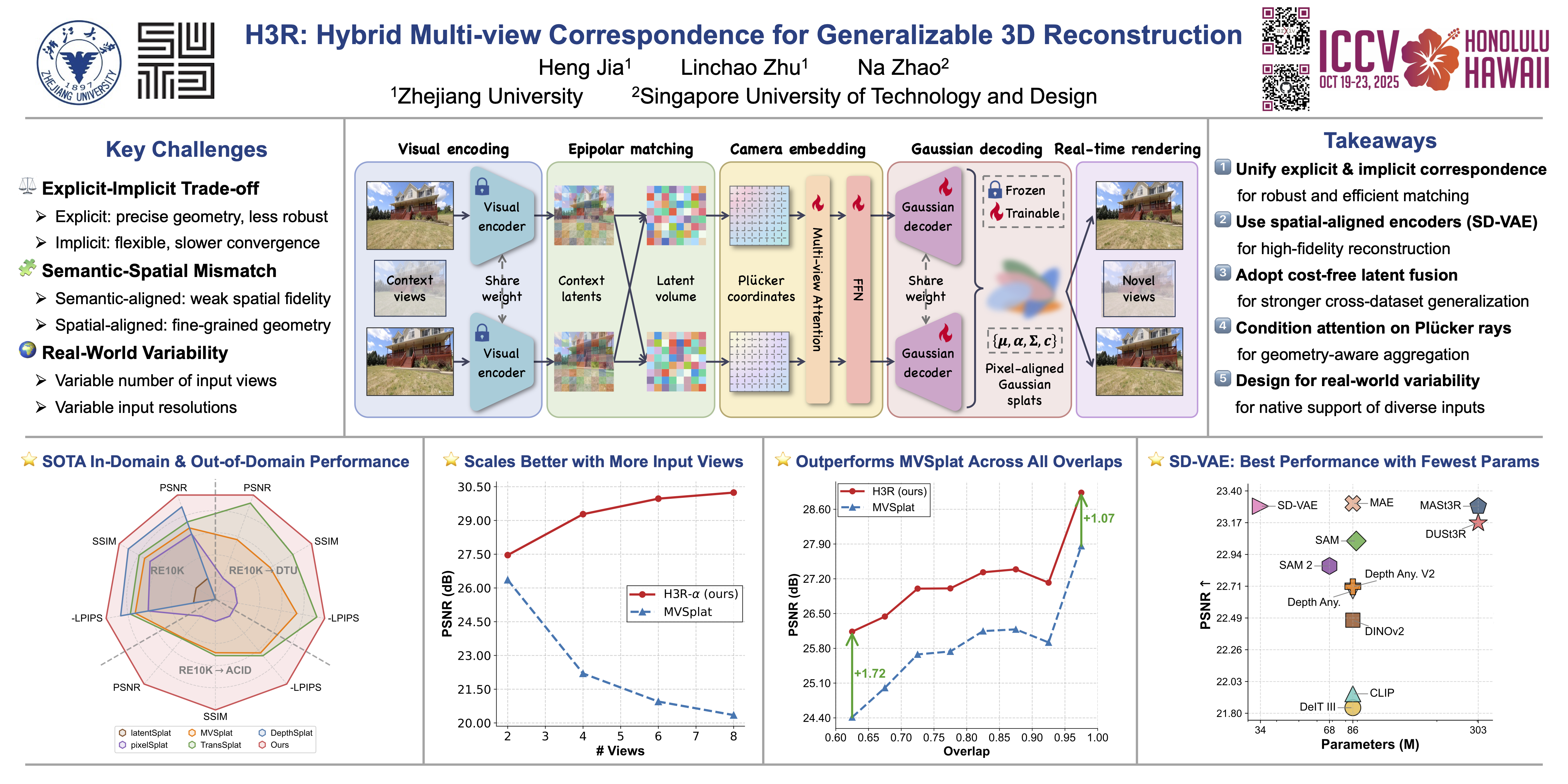
Despite recent advances in feed-forward 3DGS methods, generalizable 3D reconstruction remains challenging, particularly in the multi-view correspondence modeling. We present a hybrid framework for multi-view correspondence modeling, which integrates volumetric latent fusion with Transformer-based feature aggregation. Our framework consists of two complementary components: a latent volume that encodes view-invariant correspondences through epipolar geometry, and a camera-aware Transformer conditioned on Plücker coordinates. By combining explicit and implicit feature aggregation mechanisms, our approach enhances generalization while demonstrating accelerated convergence, requiring only half the training steps to achieve results comparable to state-of-the-art methods. Additionally, through comprehensive evaluation, we show that Visual Foundation Models trained with pixel-aligned supervision are more suitable for 3D reconstruction tasks. Our approach supports variable input views, improving reconstruction quality as view count increases while demonstrating robust cross-dataset generalization. Extensive experiments show that our method achieves state-of-the-art performance across multiple benchmarks, with PSNR improvements of 0.59 dB, 1.06 dB, and 0.22 dB on the RealEstate10K, ACID, and DTU datasets, respectively. Code will be released.