Boosting Vision Semantic Density with Anatomy Normality Modeling for Medical Vision-language Pre-training
{kind=link}
Abstract
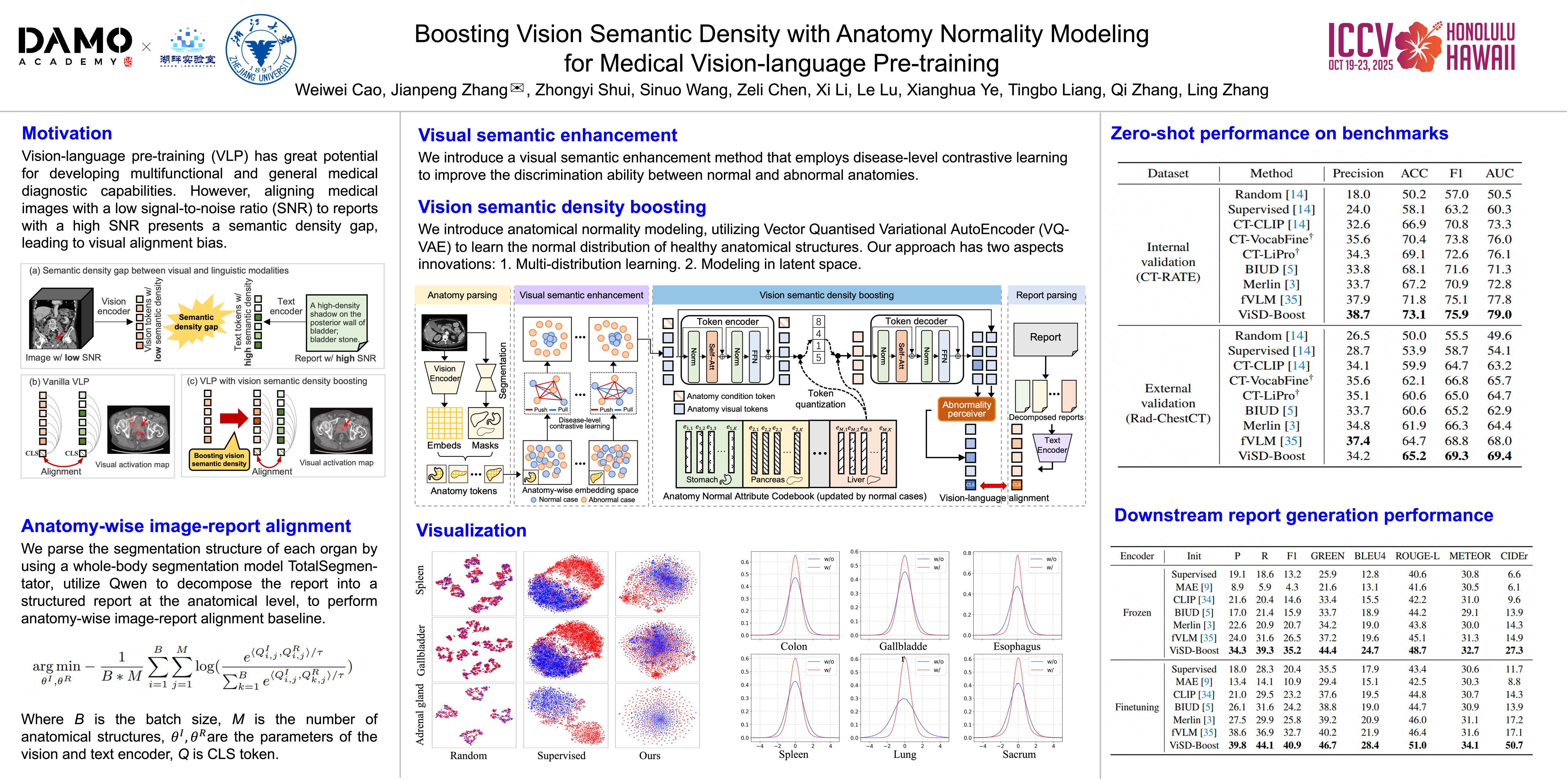
Vision-language pre-training (VLP) has great potential for developing multifunctional and general medical diagnostic capabilities. However, aligning medical images with a low signal-to-noise ratio (SNR) to reports with a high SNR presents a semantic density gap, leading to visual alignment bias. In this paper, we propose boosting vision semantic density to improve alignment effectiveness. On the one hand, we enhance visual semantics through disease-level vision contrastive learning, which strengthens the model's ability to differentiate between normal and abnormal samples for each anatomical structure. On the other hand, we introduce an anatomical normality modeling method to model the distribution of normal samples for each anatomy, leveraging VQ-VAE for reconstructing normal vision embeddings in latent space. This process amplifies abnormal signals by leveraging distribution shifts in abnormal samples, enhancing the model's perception and discrimination of abnormal attributes. The enhanced visual representation effectively captures the diagnostic-relevant semantics, facilitating more efficient and accurate alignment with the diagnostic report. We conduct extensive experiments on two chest CT datasets, CT-RATE and Rad-ChestCT, and an abdominal CT dataset, MedVL-69K, and comprehensively evaluate the diagnosis performance across multiple tasks in the chest and abdominal CT scenarios, achieving state-of-the-art zero-shot performance. Notably, our method achieved an average AUC of 84.9\% across 54 diseases in 15 organs, significantly surpassing existing methods. Additionally, we demonstrate the superior transfer learning capabilities of our pre-trained model.