Controlling Multimodal LLMs via Reward-guided Decoding
{kind=link}
Abstract
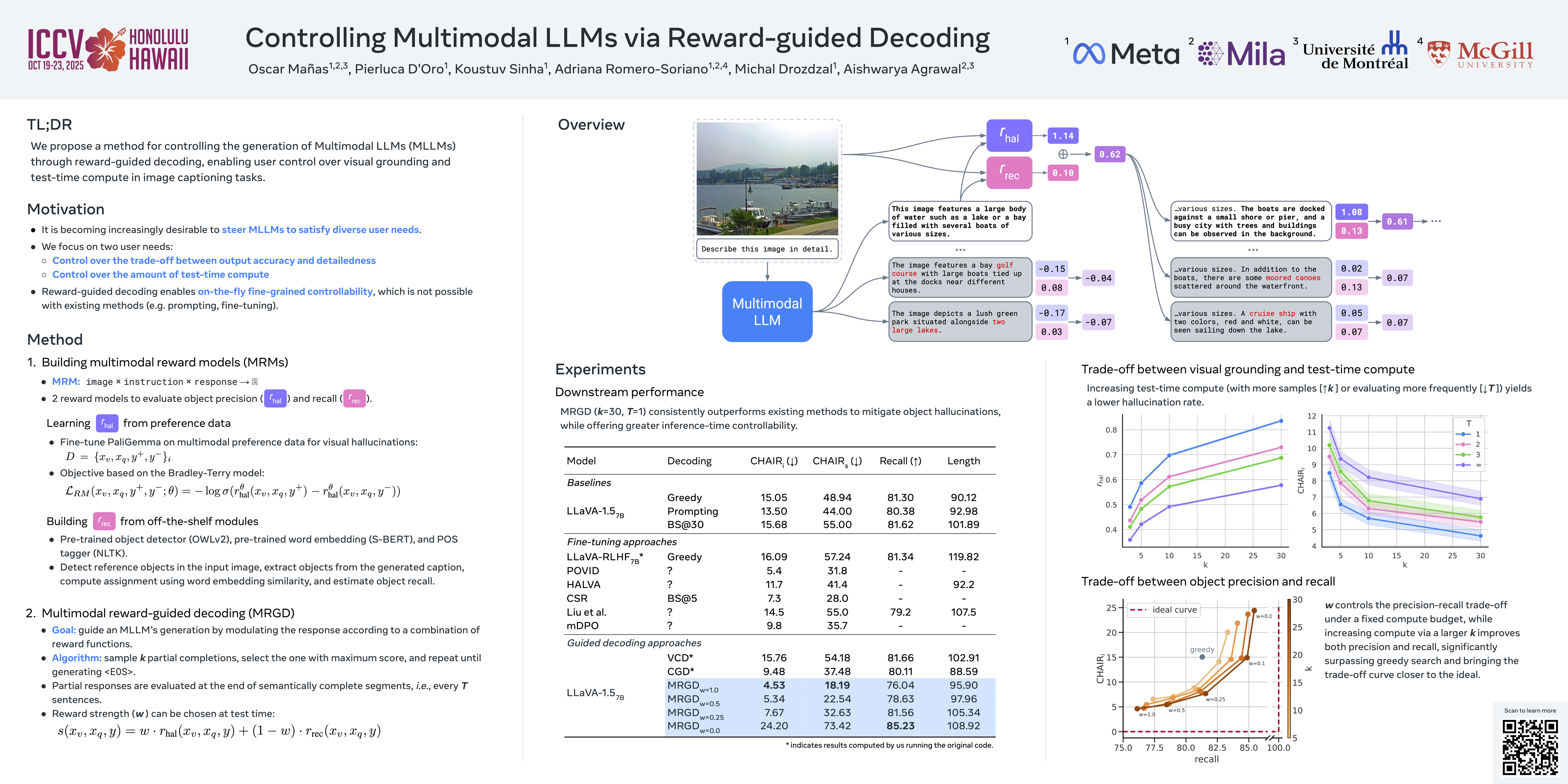
As Multimodal Large Language Models (MLLMs) gain widespread applicability, it is becoming increasingly desirable to adapt them for diverse user needs. In this paper, we study the adaptation of MLLMs through controlled decoding. To achieve this, we introduce the first method for reward-guided decoding of MLLMs and demonstrate its application in improving their visual grounding. Our method involves building reward models for visual grounding and using them to guide the MLLM's decoding process. Concretely, we build two separate reward models to independently control the degree of object precision and recall in the model's output. Our approach enables on-the-fly controllability of an MLLM's inference process in two ways: first, by giving control over the relative importance of each reward function during decoding, allowing a user to dynamically trade off between object precision and recall in image captioning tasks; second, by giving control over the breadth of the search during decoding, allowing the user to control the trade off between the amount of test-time compute and the degree of visual grounding. We evaluate our method on standard object hallucination benchmarks, showing that it provides significant controllability over MLLM inference, while matching or surpassing the performance of existing hallucination mitigation methods.