An Efficient Hybrid Vision Transformer for TinyML Applications
Fanhong Zeng ⋅ Huanan LI ⋅ Juntao Guan ⋅ Rui Fan ⋅ Tong Wu ⋅ Xilong Wang ⋅ Lai Rui
2025 Poster
{kind=link}
Abstract
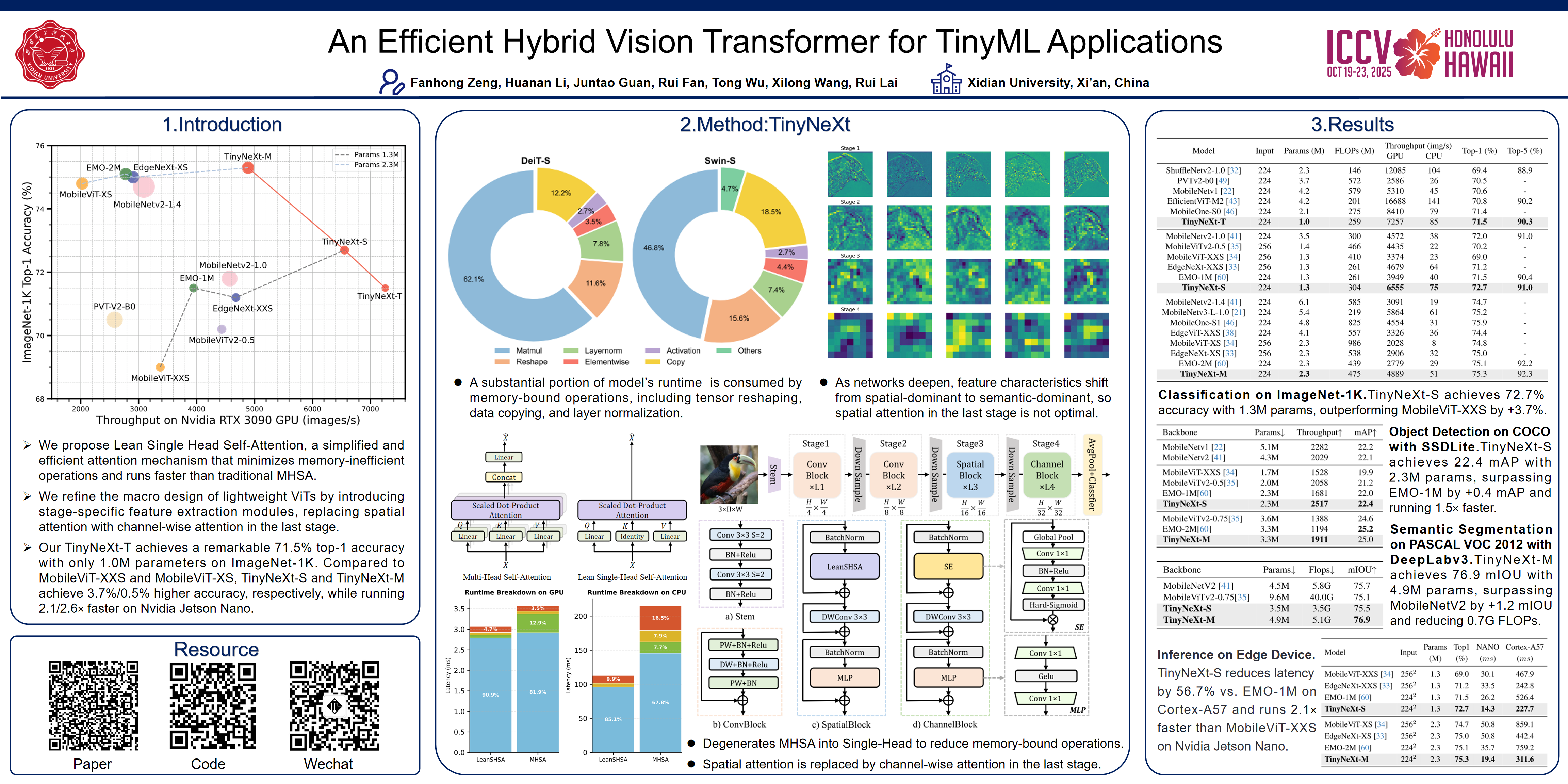
To enable the deployment of Vision Transformers on resource-constrained mobile and edge devices, the development of efficient ViT models has attracted significant attention. Researchers achieving remarkable improvements in accuracy and speed by optimizing attention mechanisms and integrating lightweight CNN modules. However, existing designs often overlook runtime overhead from memory-bound operations and the shift in feature characteristics from spatial-dominant to semantic-dominant as networks deepen. This work introduces TinyNeXt, a family of efficient hybrid ViTs for TinyML, featuring Lean Single-Head Self-Attention to minimize memory-bound operations, and a macro design tailored to feature characteristics at different stages. TinyNeXt strikes a better accuracy-speed trade-off across diverse tasks and hardware platforms, outperforming state-of-the-art models of comparable scale. For instance, our TinyNeXt-T achieves a remarkable 71.5\% top-1 accuracy with only 1.0M parameters on ImageNet-1K. Furthermore, compared to recent efficient models like MobileViT-XXS and MobileViT-XS, TinyNeXt-S and TinyNeXt-M achieve 3.7\%/0.5\% higher accuracy, respectively, while running 2.1$\times$/2.6$\times$ faster on Nvidia Jetson Nano.
Chat is not available.
Successful Page Load