Dense2MoE: Restructuring Diffusion Transformer to MoE for Efficient Text-to-Image Generation
{kind=link}
Abstract
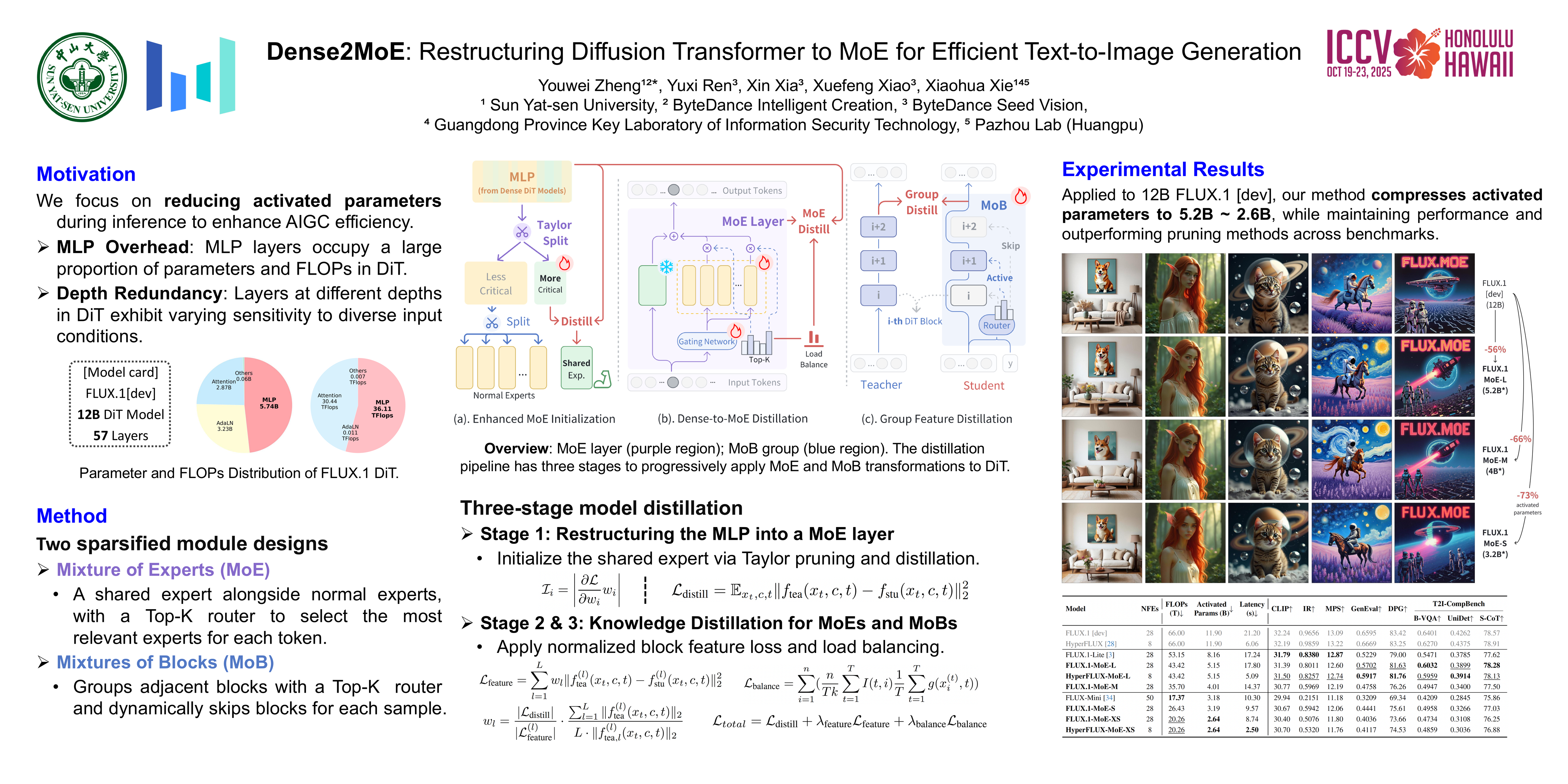
Diffusion Transformer (DiT) has demonstrated remarkable performance in text-to-image generation; however, its large parameter size results in substantial inference overhead. Existing parameter compression methods primarily focus on pruning, but aggressive pruning often leads to severe performance degradation due to reduced model capacity. To address this limitation, we pioneer the transformation of a dense DiT into a Mixture of Experts (MoE) for structured sparsification, reducing the number of activated parameters while preserving model capacity. Specifically, we replace the Feed-Forward Networks (FFNs) in DiT Blocks with MoE layers, reducing the number of activated parameters in the FFNs by 62.5\%.Furthermore, we propose the Mixture of Blocks (MoB) to selectively activate DiT blocks, thereby further enhancing sparsity.To ensure an effective dense-to-MoE conversion, we design a multi-step distillation pipeline, incorporating Taylor metric-based expert initialization, knowledge distillation with load balancing, and group feature loss for MoB optimization. We transform large diffusion transformers (e.g., FLUX.1 [dev]) into an MoE structure, reducing activated parameters by 60\% while maintaining original performance and surpassing pruning-based approaches in extensive experiments. Overall, Dense2MoE establishes a new paradigm for efficient text-to-image generation.