Language-Driven Multi-Label Zero-Shot Learning with Semantic Granularity
{kind=link}
Abstract
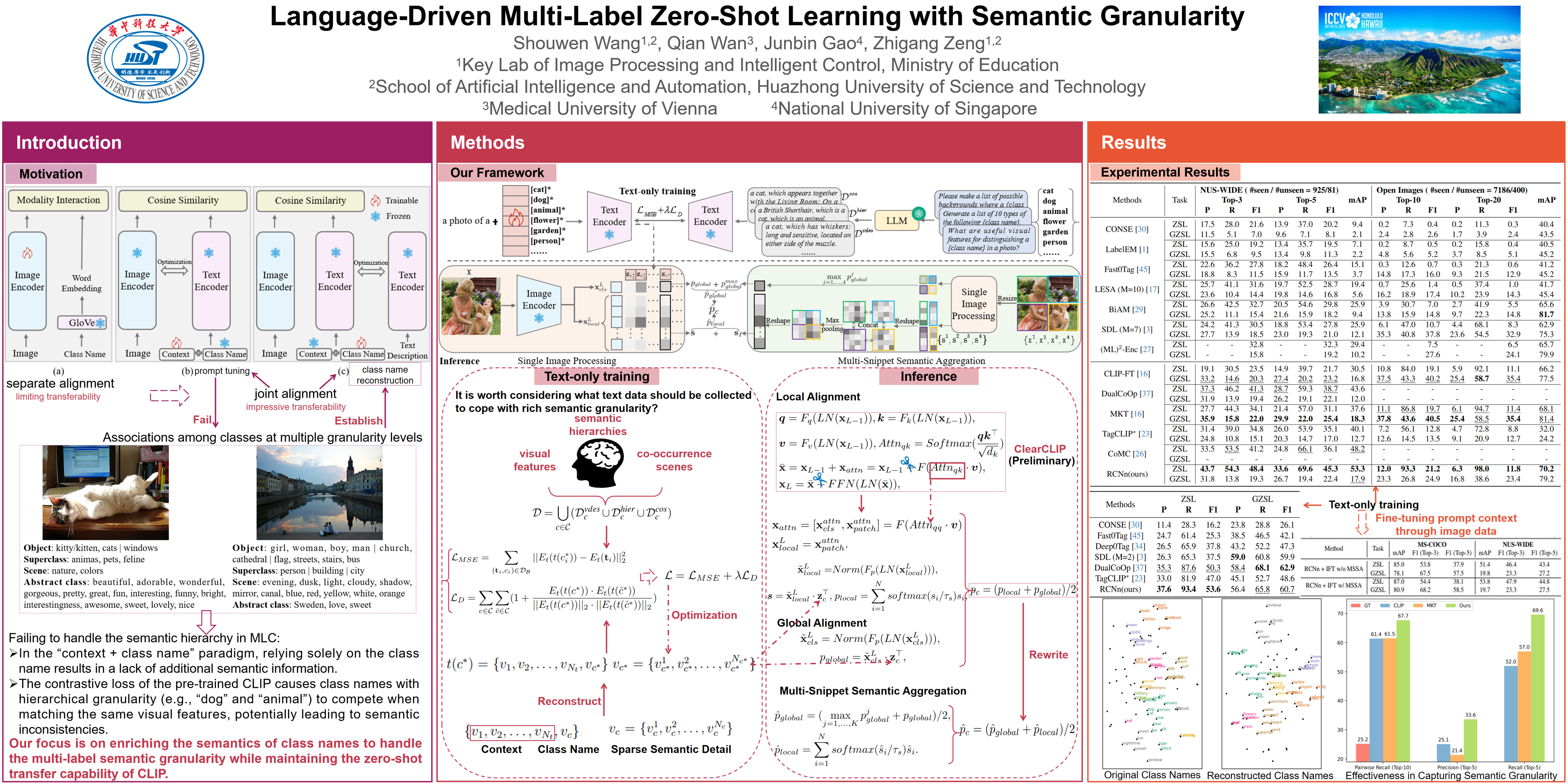
Recent methods learn class-unified prompt contexts by image data to adapt CLIP to zero-shot multi-label image classification, which achieves impressive performance. However, simply tuning prompts is insufficient to deal with novel classes across different semantic granularity levels. This limitation arises due to the sparse semantic detail in prompt class names and the hierarchical granularity competition among class names caused by CLIP’s contrastive loss. We propose a language-driven zero-shot multi-label learning framework to bridge associations among classes across multiple granularity levels through class name reconstruction. To achieve this, we first leverage a language model to generate structured text descriptions for each class, which explicitly capture (1) visual attributes, (2) hierarchical relationships, and (3) co-occurrence scenes. With the enriched descriptions, we then learn class names by extracting and aligning semantic relationships and features from them in the CLIP’s shared image-text embedding space. Furthermore, we consider that similar text descriptions among different classes may introduce ambiguities. We mitigate these ambiguities by imposing a pair-based loss on learnable class names to enhance their distinctiveness. During inference, we aggregate semantic predictions from multiple image snippets to reinforce the identification of classes across different granularity levels. Comprehensive experiments demonstrate that our method surpasses state-of-the-art methods in multi-label zero-shot learning and effectively handles novel classes across different granularity levels.