LV-MAE: Learning Long Video Representations through Masked-Embedding Autoencoders
{kind=link}
Abstract
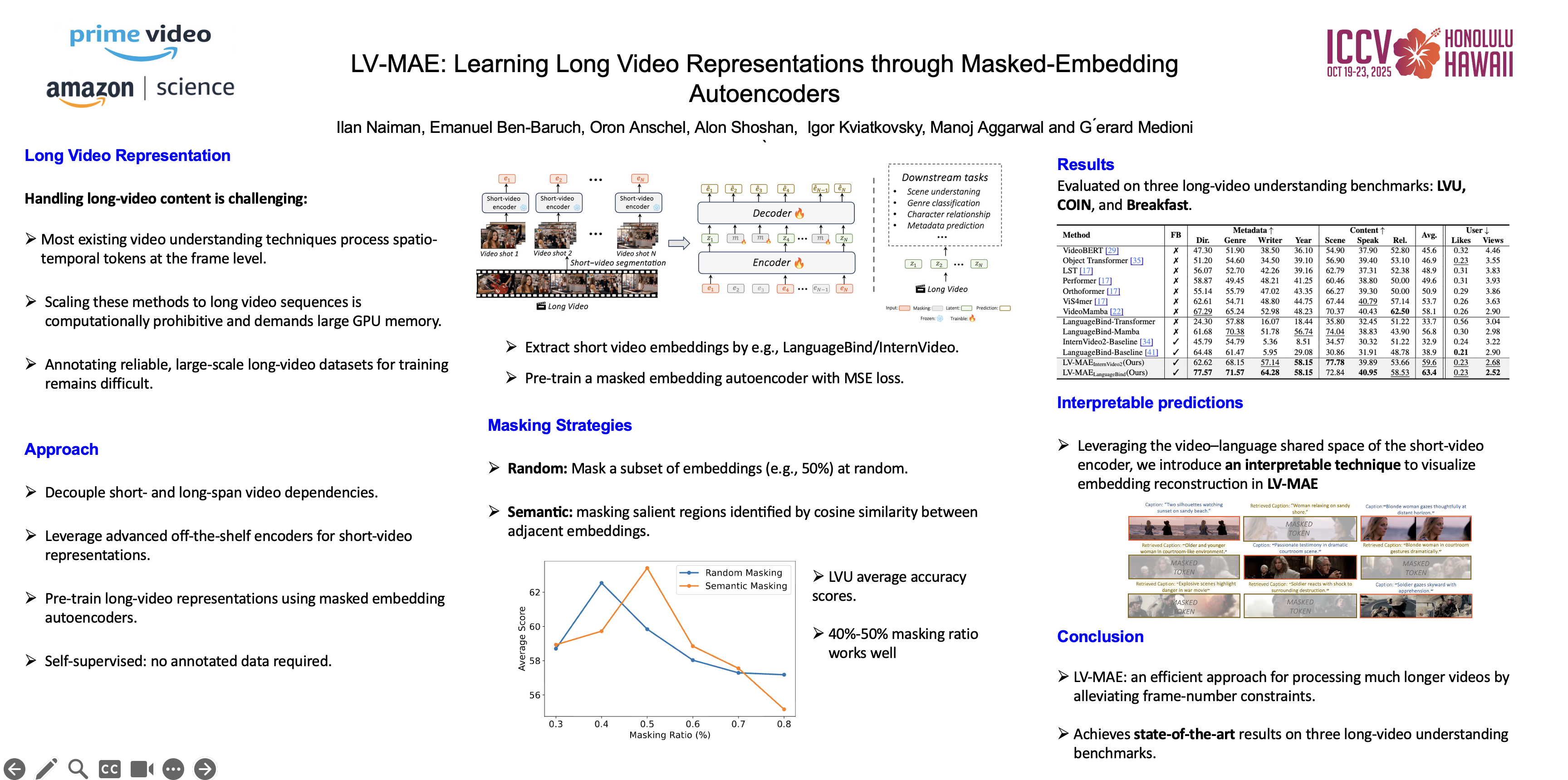
In this work, we introduce long-video masked-embedding autoencoders (LV-MAE), a self-supervised learning framework for long video representation.Our approach treats short- and long-span dependencies as two separate tasks.Such decoupling allows for a more intuitive video processing where short-span spatiotemporal primitives are first encoded and are then used to capture long-range dependencies across consecutive video segments. To achieve this, we leverage advanced off-the-shelf multimodal encoders to extract representations from short segments within the long video, followed by pre-training a masked-embedding autoencoder capturing high-level interactions across segments.LV-MAE is highly efficient to train and enables the processing of much longer videos by alleviating the constraint on the number of input frames.Furthermore, unlike existing methods that typically pre-train on short-video datasets, our approach offers self-supervised pre-training using long video samples (e.g., 20+ minutes video clips) at scale.Using LV-MAE representations, we achieve state-of-the-art results on three long-video benchmarks -- LVU, COIN, and Breakfast -- employing only a simple classification head for either attentive or linear probing.Finally, to assess LV-MAE pre-training and visualize its reconstruction quality, we leverage the video-language aligned space of short video representations to monitor LV-MAE through video-text retrieval.Our code will be made available upon publication.