One Object, Multiple Lies: A Benchmark for Cross-task Adversarial Attack on Unified Vision-Language Models
{kind=link}
Abstract
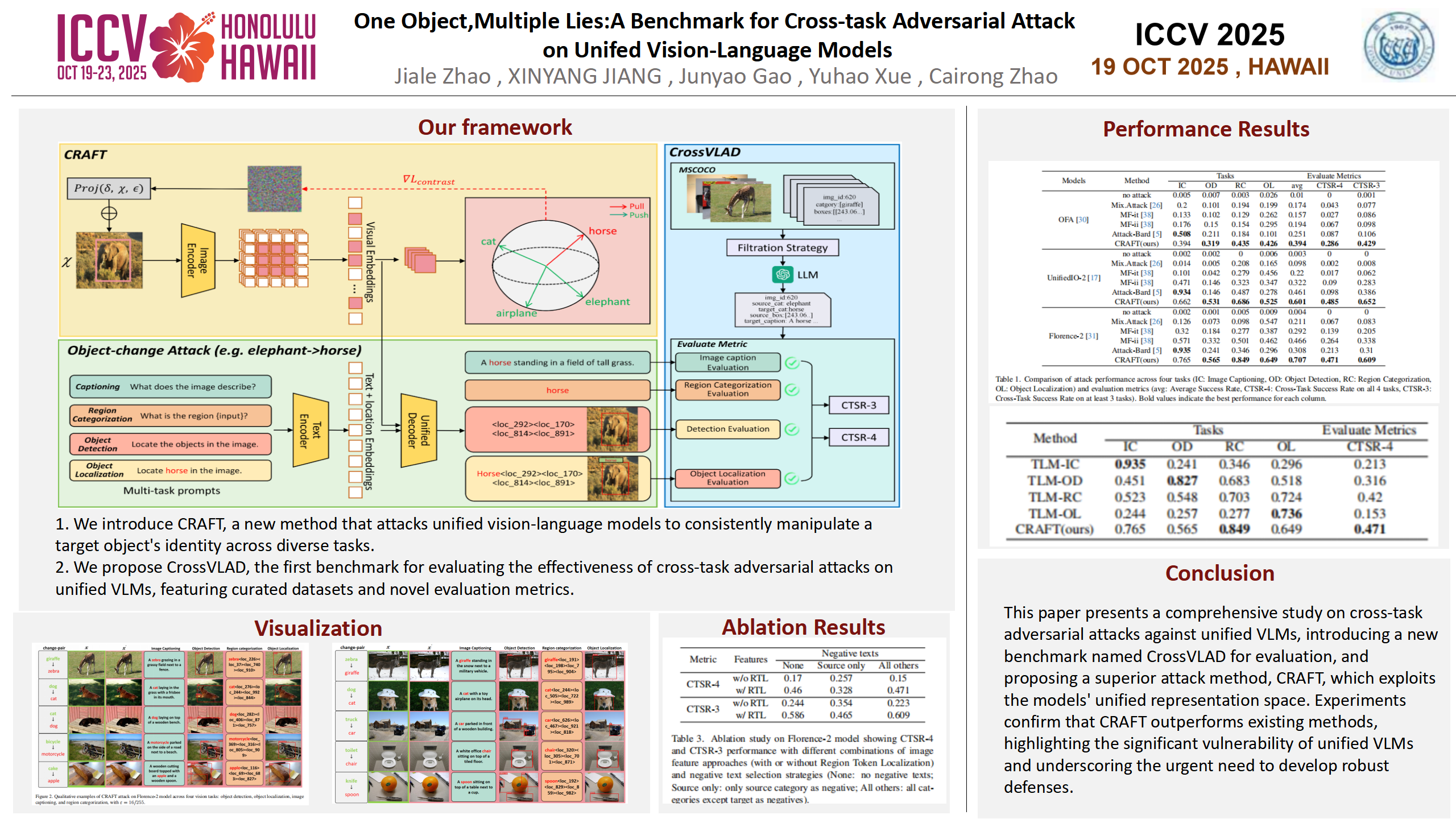
Unified vision-language models (VLMs) have recently shown remarkable progress, enabling a single model to flexibly address diverse tasks through different instructions within a shared computational architecture. This instruction-based control mechanism creates unique security challenges, as adversarial inputs must remain effective across multiple task instructions that may be unpredictably applied to process the same malicious content. In this paper, we introduce CrossVLAD, a new benchmark dataset carefully curated from MSCOCO with GPT-4-assisted annotations for systematically evaluating cross-task adversarial attacks on unified VLMs. CrossVLAD centers on the object-change objective—consistently manipulating a target object's classification across four downstream tasks—and proposes a novel success rate metric that measures simultaneous misclassification across all tasks, providing a rigorous evaluation of adversarial transferability. To tackle this challenge, we present CRAFT (Cross-task Region-based Attack Framework with Token-alignment), an efficient region-centric attack method. Extensive experiments on Florence-2 and other popular unified VLMs demonstrate that our method outperforms existing approaches in both overall cross-task attack performance and targeted object-change success rates, highlighting its effectiveness in adversarially influencing unified VLMs across diverse tasks.