I Am Big, You Are Little; I Am Right, You Are Wrong
{kind=link}
Abstract
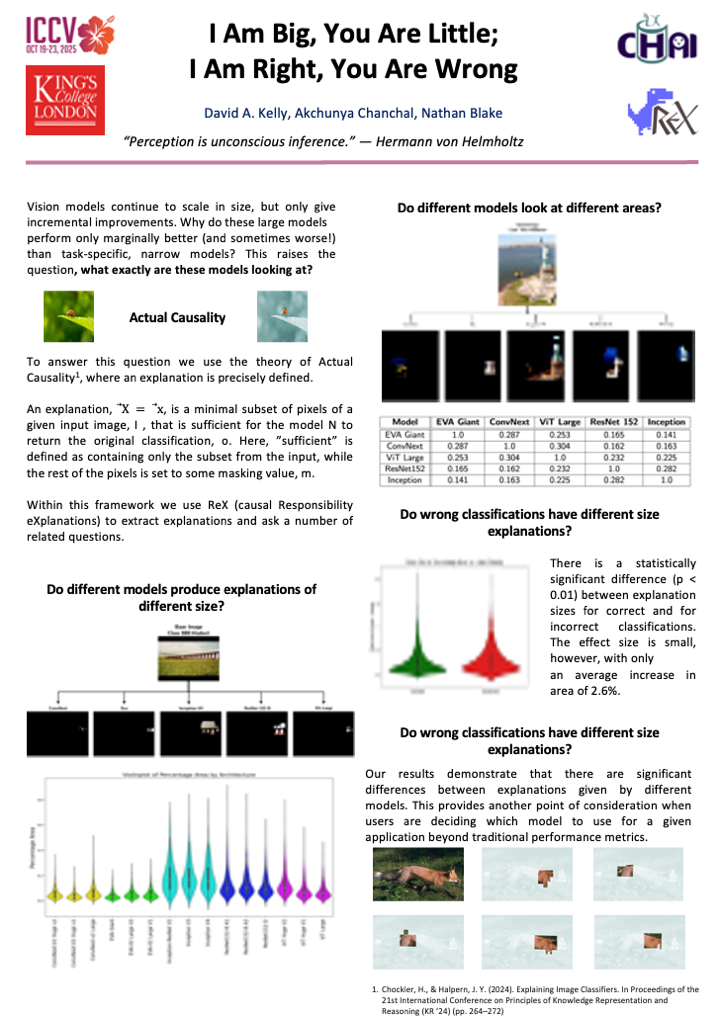
Machine learning for image classification is an active and rapidly developing field. With the proliferation of classifiers of different sizes and different architectures, the problem of choosing the right model becomes more and more important. While we can assess a model's classification accuracy statistically, our understanding of the way these models work is unfortunately quite limited. In order to gain insight into the decision-making process of different vision models, we propose using minimal sufficient pixels sets. These pixels capture the essence of an image through the lens of the model. By comparing position, overlap and size of sets of pixels, we identify that different architectures have statistically different minimal pixels sets, in both size and position. In particular, ConvNext and EVA models differ markedly from the others. We also identify that images which are misclassified are associated with statistically significant larger pixels sets than correct classifications.