Hybrid-Tower: Fine-grained Pseudo-query Interaction and Generation for Text-to-Video Retrieval
Bangxiang Lan ⋅ Ruobing Xie ⋅ Ruixiang Zhao ⋅ Xingwu Sun ⋅ Zhanhui Kang ⋅ Gang Yang ⋅ Xirong Li
2025 Poster
{kind=link}
Abstract
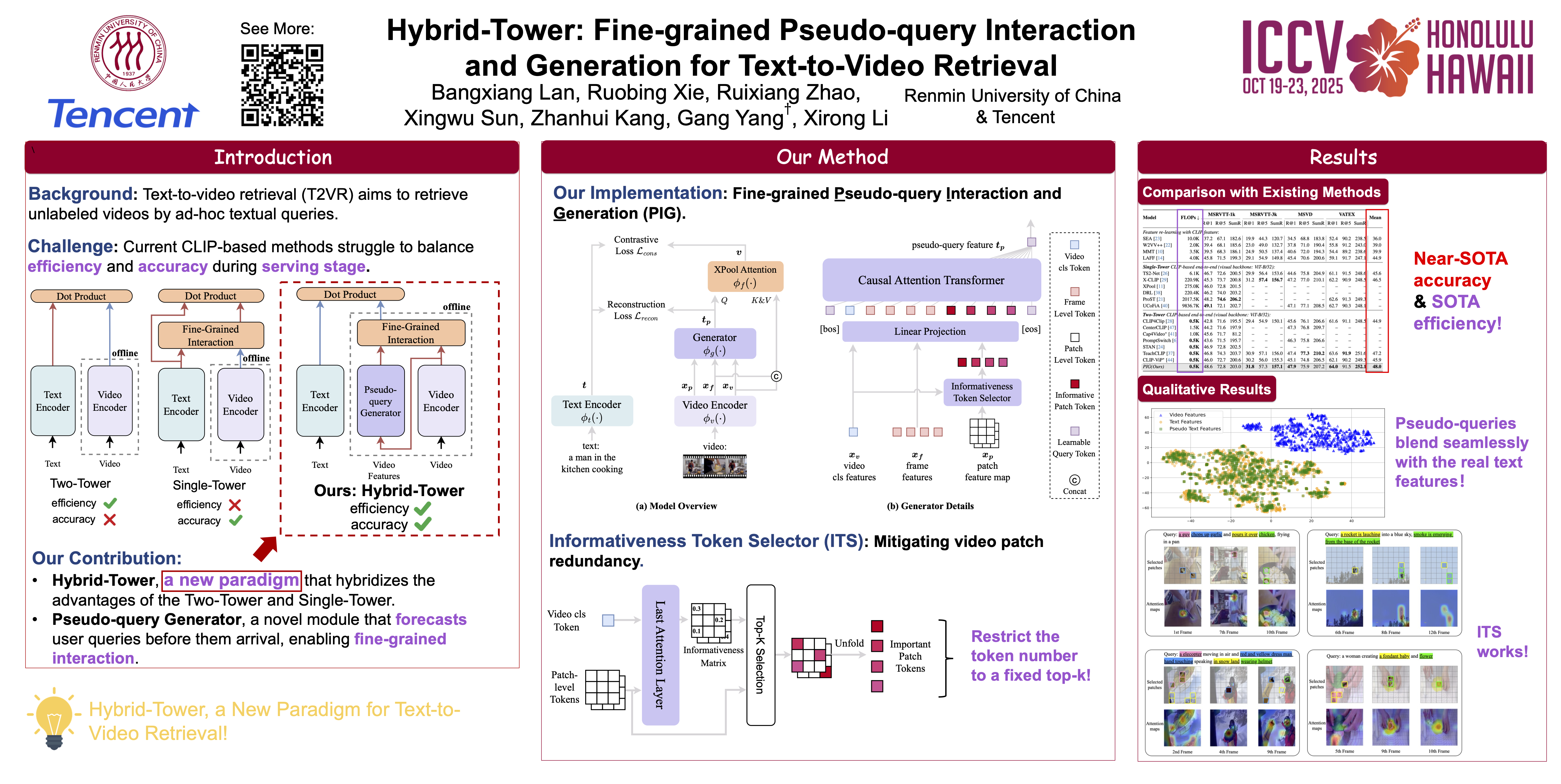
The Text-to-Video Retrieval (T2VR) task aims to retrieve unlabeled videos by textual queries with the same semantic meanings. Recent CLIP-based approaches have explored two frameworks: Two-Tower versus Single-Tower framework, yet the former suffers from low effectiveness, while the latter suffers from low efficiency. In this study, we explore a new Hybrid-Tower framework that can hybridize the advantages of the Two-Tower and Single-Tower framework, achieving high effectiveness and efficiency simultaneously. We propose a novel hybrid method, Fine-grained Pseudo-query Interaction and Generation for T2VR, \ie F-Pig, which includes a new pseudo-query generator designed to generate a pseudo-query for each video. This enables the video feature and the textual features of pseudo-query to interact in a fine-grained manner, similar to the Single-Tower approaches to hold high effectiveness, even before the real textual query is received. Simultaneously, our method introduces no additional storage or computational overhead compared to the Two-Tower framework during the inference stage, thus maintaining high efficiency. Extensive experiments on five commonly used text-video retrieval benchmarks, including MSRVTT-1k, MSRVTT-3k, MSVD, VATEX and DiDeMo, demonstrate that our method achieves a significant improvement over the baseline, with an increase of $1.6\% \sim 3.9\%$ in R@1.
Chat is not available.
Successful Page Load