V.I.P. : Iterative Online Preference Distillation for Efficient Video Diffusion Models
{kind=link}
Abstract
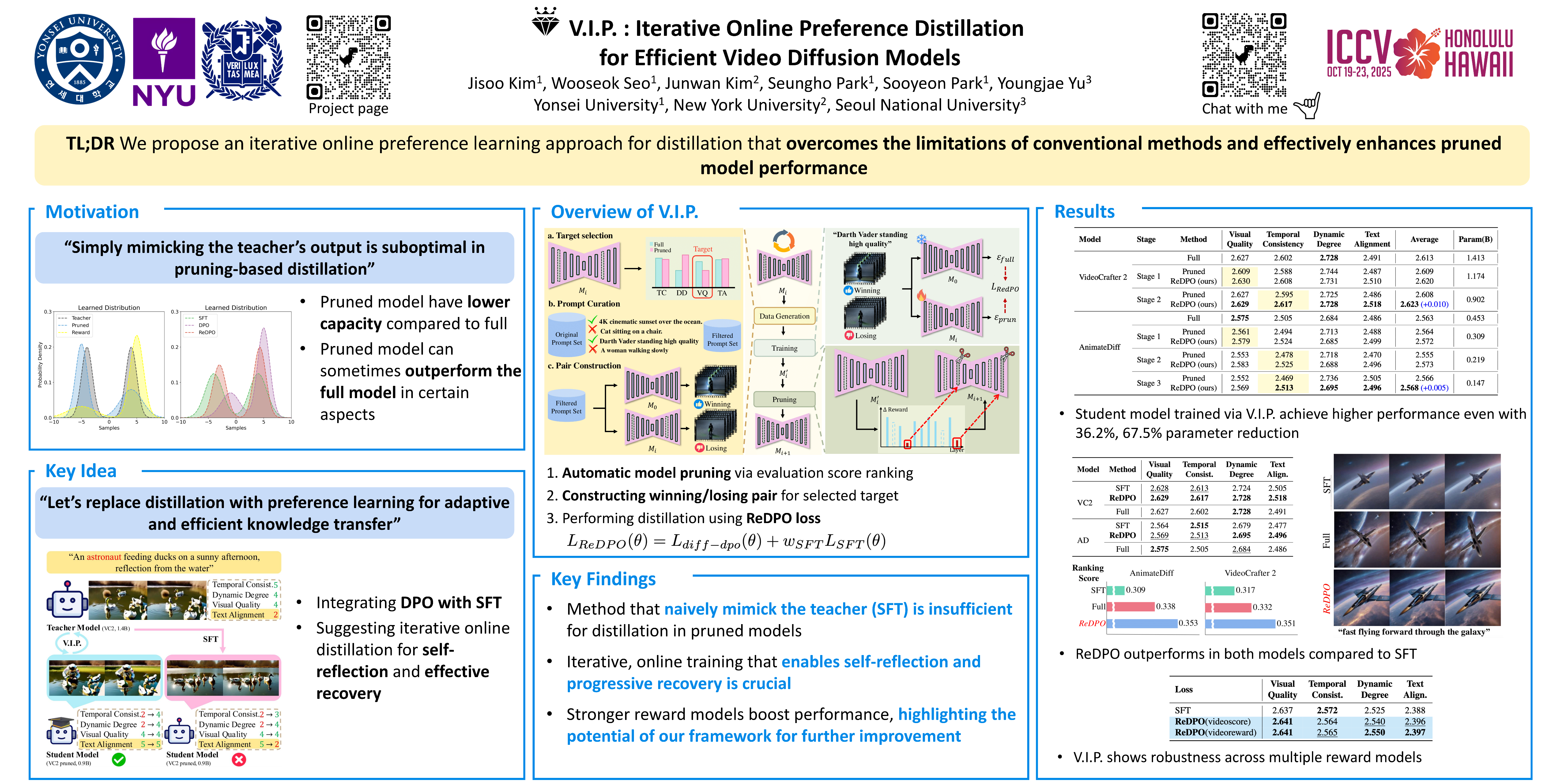
Despite the remarkable success of text-to-video (T2V) generation, its large memory requirements limit deployment in resource-constrained environments, leading to extensive research on model pruning and knowledge distillation to enhance efficiency while preserving performance. However, existing distillation methods primarily rely on supervised fine-tuning (SFT) loss, which, due to the reduced capacity of pruned models, struggles to capture fine-grained details. This leads to averaged predictions and ultimately degrades overall quality. To mitigate this challenge, we propose an effective distillation method, \loss, that combines DPO and SFT, leveraging DPO’s ability to guide the student model in learning preferences for its limiting properties while de-emphasizing less critical ones, complemented by SFT to enhance overall performance. Along with \loss, our framework, \ours includes filtering and curation for high-quality datasets, as well as a step-by-step online approach for more effective learning. We implement our method on two baseline models, VideoCrafter2 and AnimateDiff, achieving parameter reduction of 36.2\% in VideoCrafter and 67.5\% in AnimateDiff motion module, while maintaining or even surpassing the performance of full models. Further experiments validate the effectiveness of our \loss loss and \ours framework, demonstrating their impact on efficient and high-quality video generation.