Training-Free Personalization via Retrieval and Reasoning on Fingerprints
{kind=link}
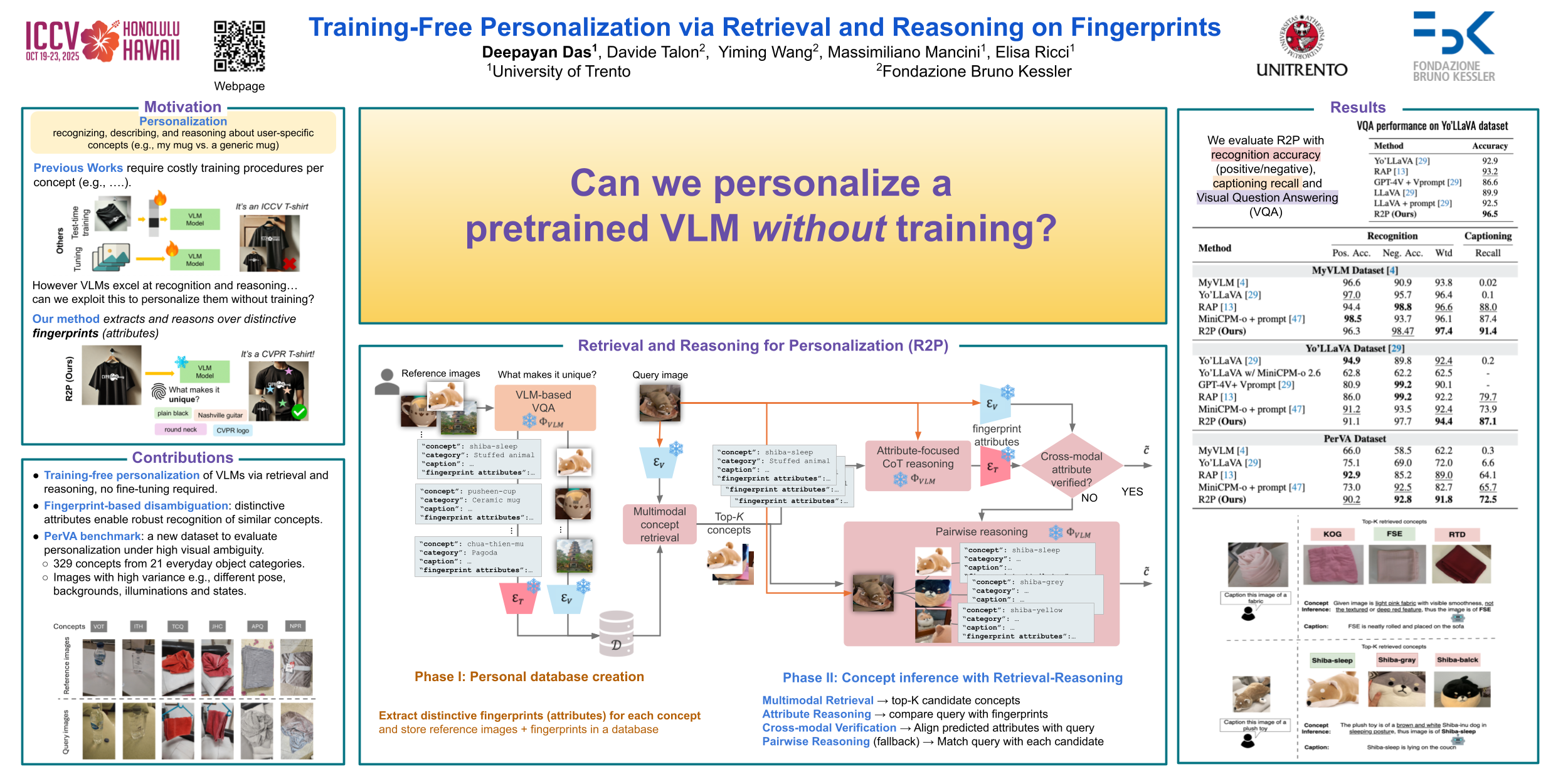
Abstract
Vision Language Models (VLMs) have lead to major improvements in multimodal reasoning, yet they still struggle to understand user-specific concepts. Existing personalization methods address this limitation butheavily rely on training procedures, that can be either costly or unpleasant to individual users.We depart from existing work, and for the first time explore the training-free setting in the context of personalization. We propose a novel method, Retrieval and Reasoning for Personalization (R2P), leveraging internal knowledge of VLMs. First, we leverage VLMs to extract the concept fingerprint, i.e., key attributes uniquely defining the concept within its semantic class. When a query arrives, the most similar fingerprints are retrieved and scored via chain of thought reasoning. To reduce the risk of hallucinations, the scores are validated through cross-modal verification at the attribute level:in case of a discrepancy between the scores, R2P refines the concept association viapairwise multimodal matching, where the retrieved fingerprints and their images aredirectly compared with the query.We validate R2P on two publicly available benchmarks and a newly introduced dataset, Personal Concepts with Visual Ambiguity (PerVA), for concept identification highlighting challenges in visual ambiguity. R2P consistently outperforms state-of-the-art approaches on various downstream tasks across all benchmarks. Code will be available upon acceptance.