MixA-Q: Revisiting Activation Sparsity for Vision Transformers from a Mixed-Precision Quantization Perspective
{kind=link}
Abstract
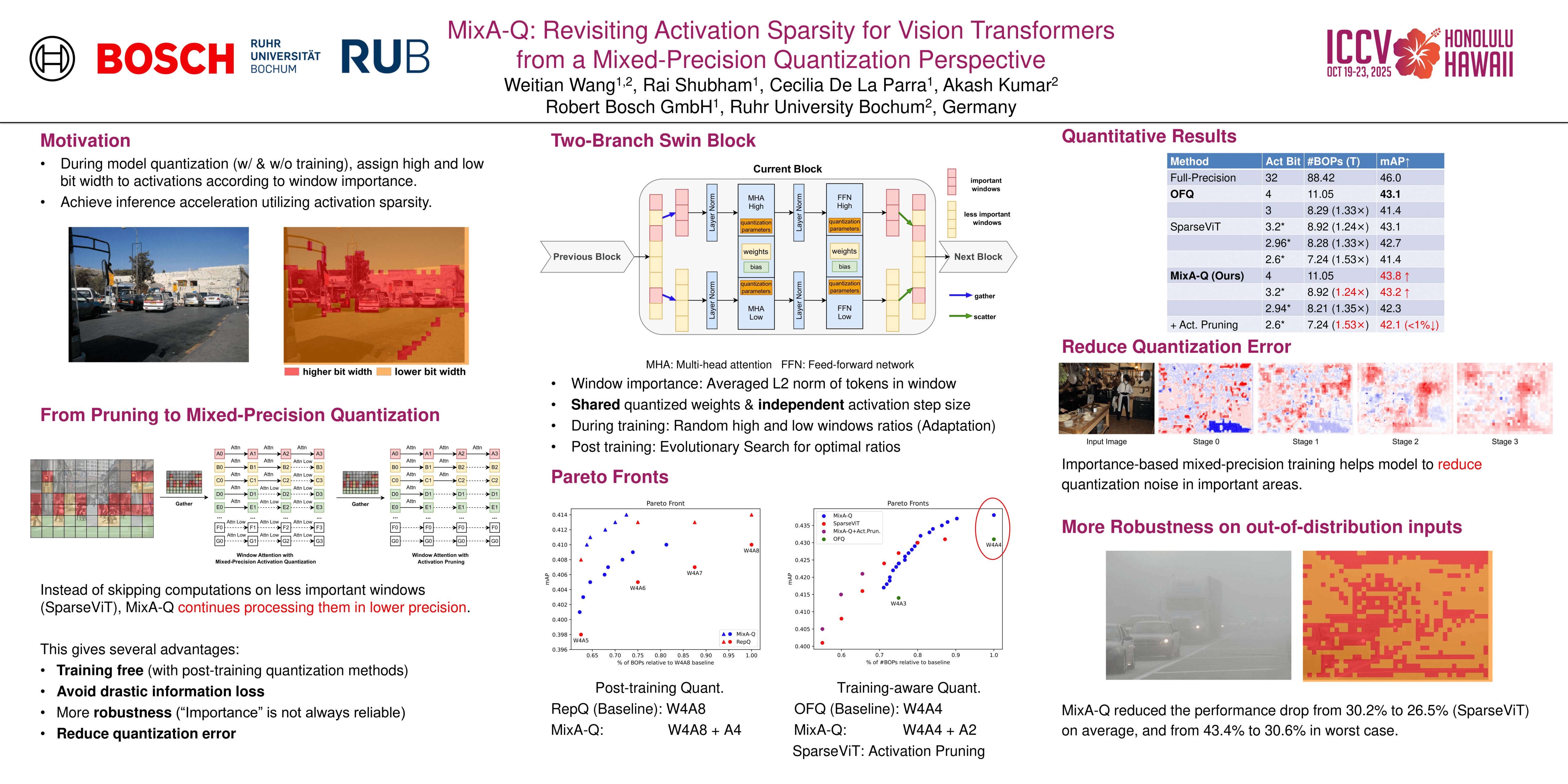
In this paper, we propose MixA-Q, a mixed-precision activation quantization framework that leverages intra-layer activation sparsity (a concept widely explored in activation pruning methods) for efficient inference of quantized window-based vision transformers. For a given uniform-bit quantization configuration, MixA-Q separates the batched window computations within Swin blocks and assigns a lower bit width to the activations of less important windows,improving the trade-off between model performance and efficiency. We introduce a Two-Branch Swin Block that processes activations separately in high- and low-bit precision, enabling seamless integration of our method with most quantization-aware training (QAT) and post-training quantization (PTQ) methods, or with simple modifications. Our experimental evaluations over the COCO dataset demonstrate that MixA-Q achieves a training-free 1.35× computational speedup without accuracy loss in PTQ configuration. With QAT, MixA-Q achieves a lossless 1.25× speedup and a 1.53× speedup with only a 1\% mAP drop by incorporating activation pruning. Notably, by reducing the quantization error in important regions, our sparsity-aware quantization adaptation improves the mAP of the quantized W4A4 model (with both weights and activations in 4-bit precision) by 0.7\%, reducing quantization degradation by 24\%.