DGTalker: Disentangled Generative Latent Space Learning for Audio-Driven Gaussian Talking Heads
{kind=link}
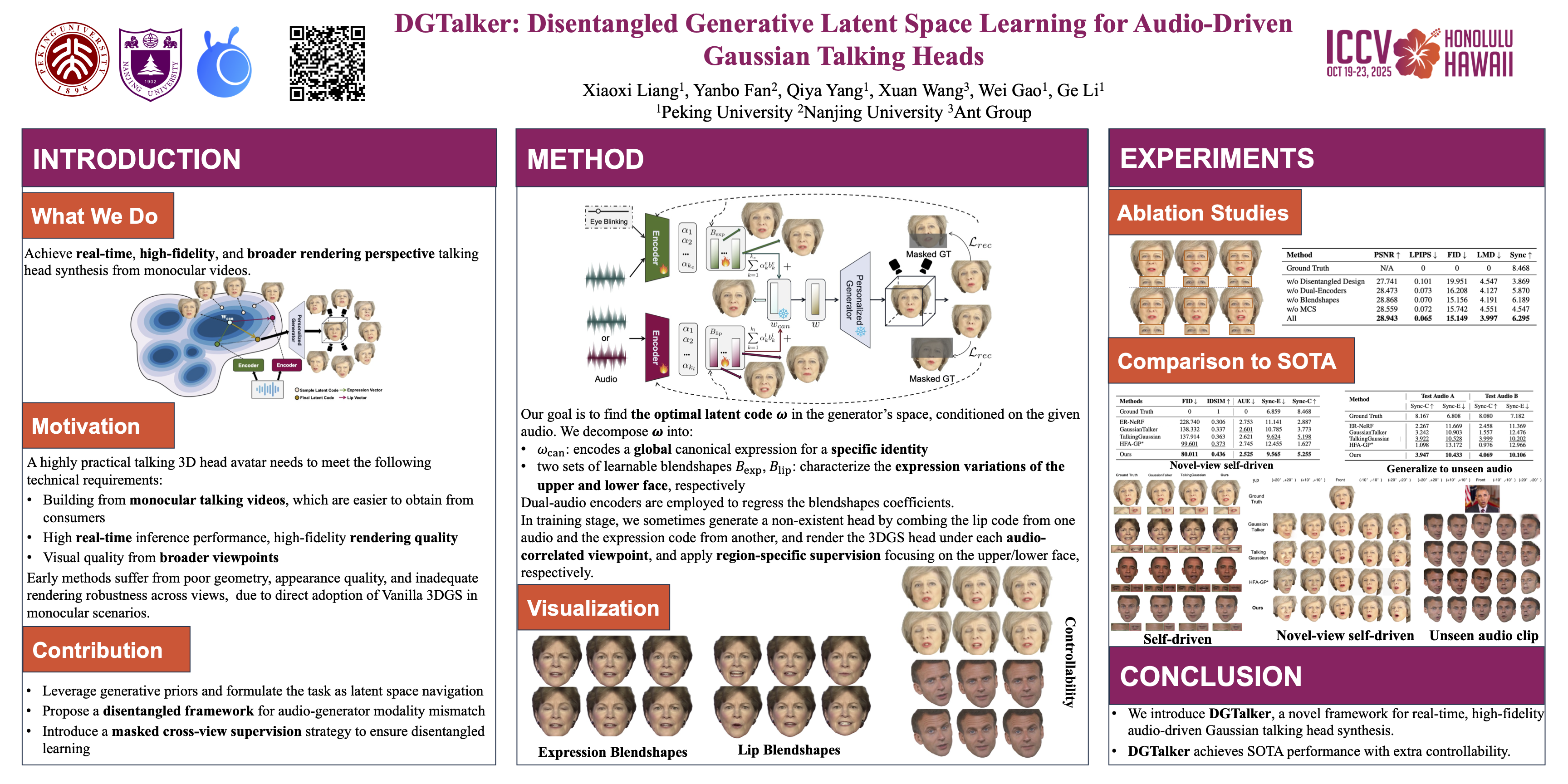
Abstract
In this work, we investigate the generation of high-fidelity, audio-driven 3D Gaussian talking heads from monocular videos. We present DGTalker, an innovative framework designed for real-time, high-fidelity, and 3D-aware talking head synthesis. By leveraging Gaussian generative priors and treating the task as a latent space navigation problem, our method effectively alleviates the lack of 3D information and the low-quality detail reconstruction caused by overfitting to training views in monocular videos, which has been a longstanding challenge in existing 3DGS-based approaches. To ensure precise lip synchronization and nuanced expression control, we propose a disentangled latent space navigation framework that independently models lip motion and upper-face expressions. Additionally, we introduce an effective masked cross-view supervision strategy to enable robust learning within the disentangled latent space. We conduct extensive experiments and demonstrate that DGTalker surpasses current state-of-the-art methods in visual quality, motion accuracy, and controllability.