LIRA: Inferring Segmentation in Large Multi-modal Models with Local Interleaved Region Assistance
{kind=link}
Abstract
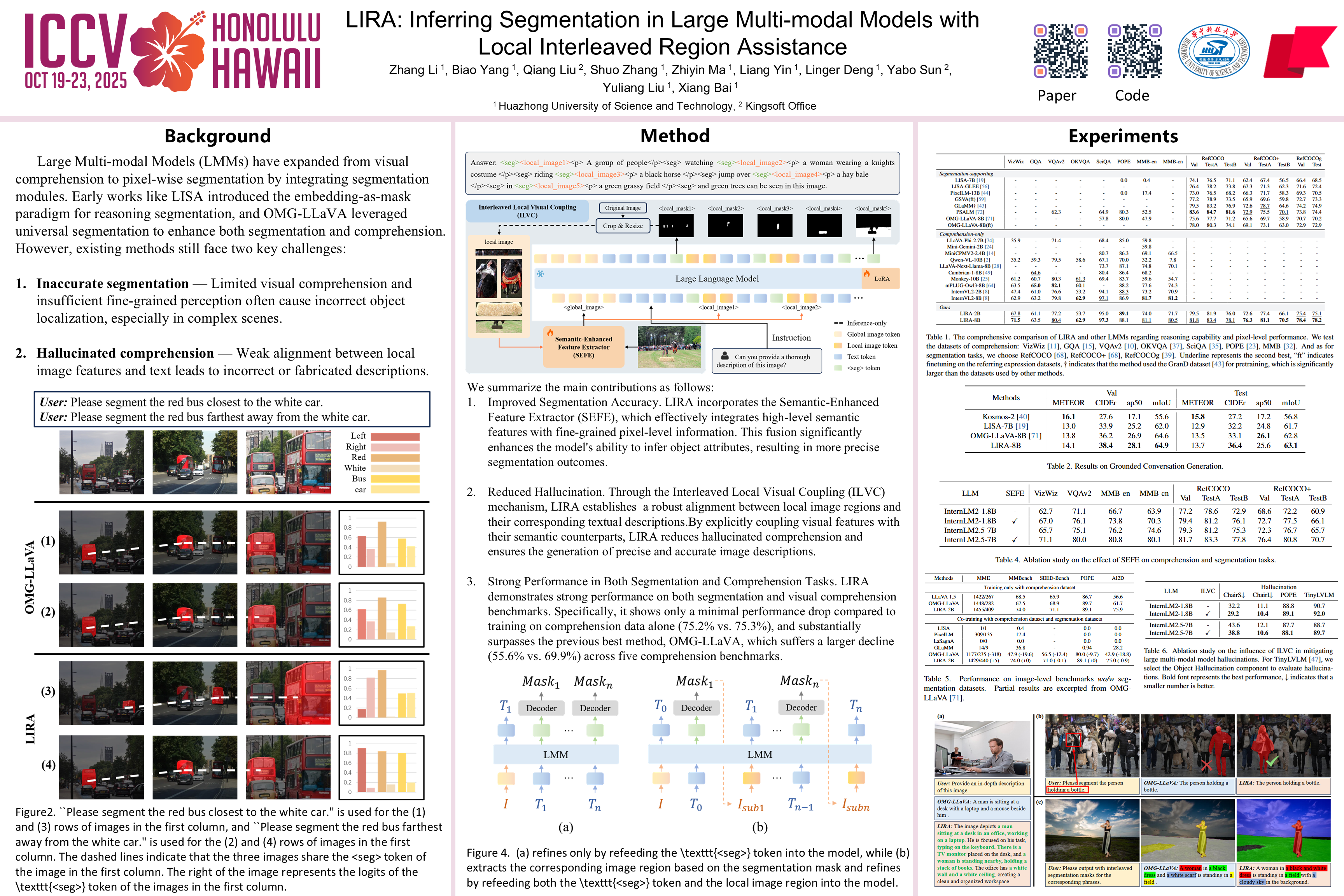
While large multi-modal models (LMMs) demonstrate promising capabilities in segmentation and comprehension, they still struggle with two limitations: inaccurate segmentation and hallucinated comprehension. These challenges stem primarily from constraints in weak visual comprehension and a lack of fine-grained perception. To alleviate these limitations, we propose LIRA, a framework that capitalizes on the complementary relationship between visual comprehension and segmentation via two key components: (1) Semantic-Enhanced Feature Extractor (SEFE) improves object attribute inference by fusing semantic and pixel-level features, leading to more accurate segmentation; (2) Interleaved Local Visual Coupling (ILVC) autoregressively generates local descriptions after extracting local features based on segmentation masks, offering fine-grained supervision to mitigate hallucinations. Furthermore, we find that the precision of object segmentation is positively correlated with the latent related semantics of the