Multidimensional Byte Pair Encoding: Shortened Sequences for Improved Visual Data Generation
{kind=link}
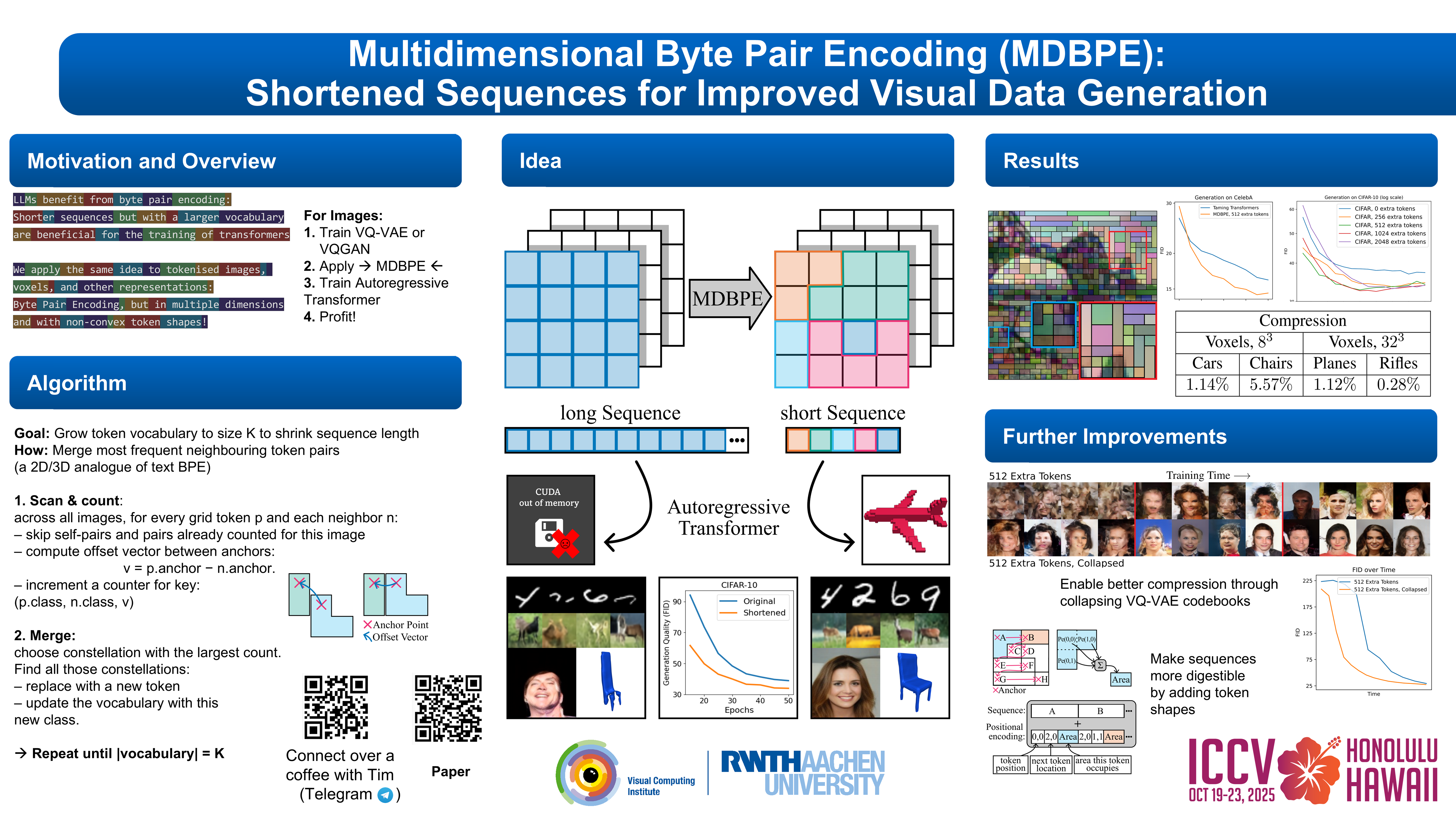
Abstract
In language processing, transformers benefit greatly from characters being condensed into word fragments, building outputs from a larger vocabulary of bigger pieces. This is often done with Byte Pair Encoding. In the context of images, tokenisation of visual data is usually limited to regular grids obtained from quantisation methods, not using such further abstraction of regions.Our work improves tokenisation of visual data by bringing Byte Pair Encoding from 1D to multiple dimensions, as a complementary add-on to existing compression. We achieve this through counting constellations of token pairs and replacing the most frequent token pair with a newly introduced token. Our approach only increases computation time by a factor of 2 for images, making it applicable even to large datasets like ImageNet within minutes on consumer hardware. This is a lossless preprocessing step. We further propose how networks can digest the new tokens that are no longer in a regular grid.Our evaluation shows improved training and inference performance of transformers on visual data achieved by compressing frequent constellations of tokens: The resulting sequences have more uniformly distributed information content, e.g. by condensing empty regions in an image into single tokens. As our experiments show, these condensed sequences are easier to process.